有學過6
sigma的同學, 一定知道 Minitab這套軟體, 因為它把6 sigma實用化了. 過去 Minitab 並沒有中文版, 但對岸有人將它漢化後, 官方也出簡體中文版, 使用簡體中文版會比英文版更friendly, 但畢竟兩岸語文還是有差異, 尤其專有名詞上的差異更讓人難以適從, 例如常態分配 v.s. 正态分布; 品質 v.s. 质量; 巨集 v.s. 宏; 變異數分析
v.s.方差分析; 進階 v.s. 高级…
官方目前沒有繁體中文版.~可惜! 希望 Minitab TWN公司能早日完成繁體中文版的 Minitab. ~期待!
先前談到 Tutorials 教學課程, 了解如何使用 Minitab 各項功能。而在Help 協助 > StatGuide 統計指南中, 則對於輸出的結果有詳細的解釋說明:

Basic Statistics > Two Proportions

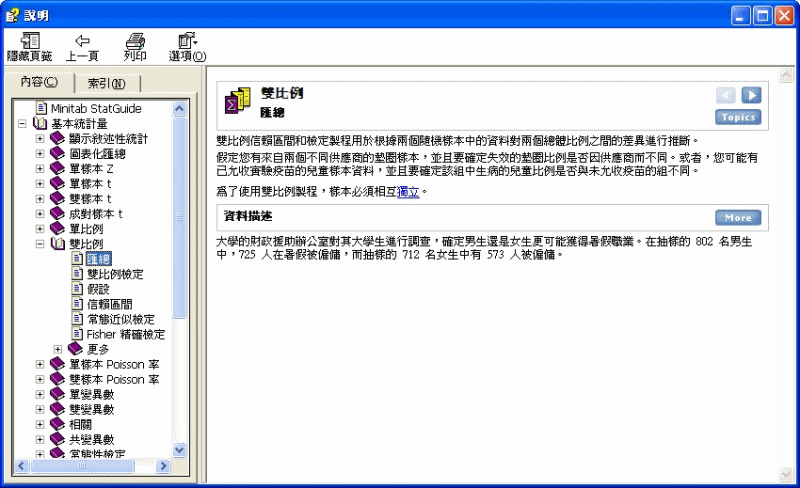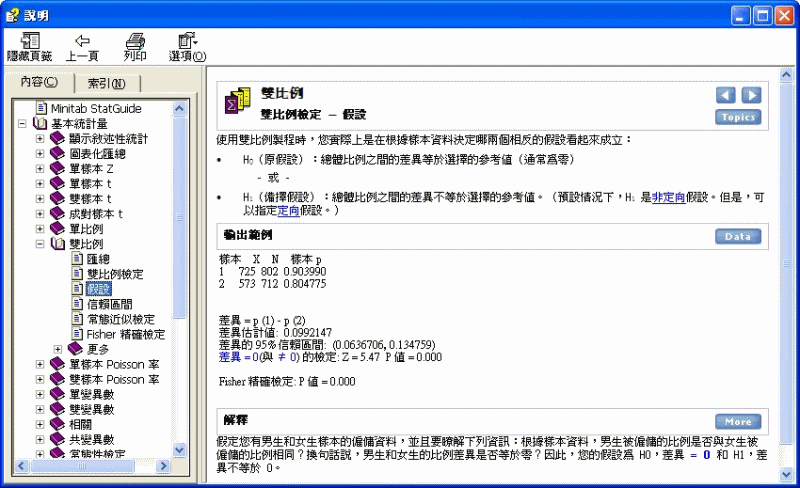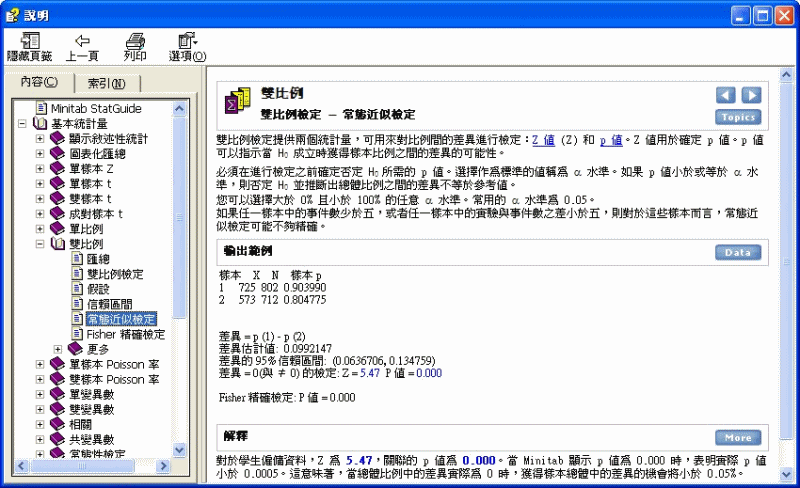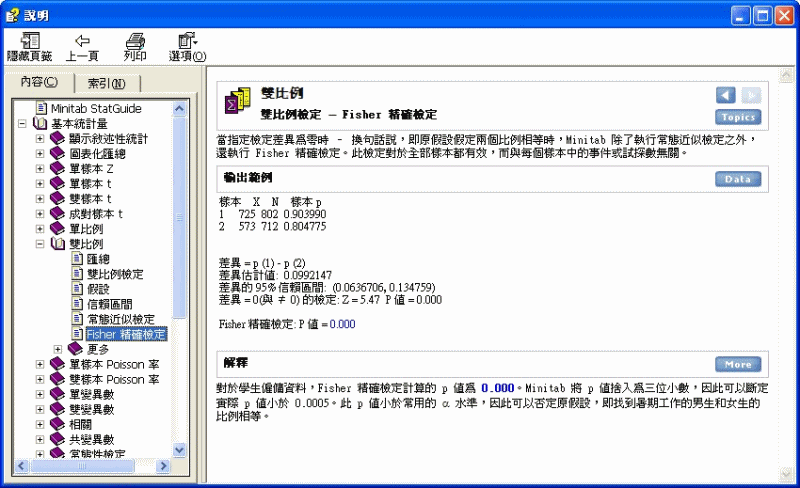
雙比例 > 匯總
雙比例信賴區間和檢定製程用於根據兩個隨機樣本中的資料對兩個總體比例之間的差異進行推斷。
假定您有來自兩個不同供應商的墊圈樣本,並且要確定失效的墊圈比例是否因供應商而不同。或者,您可能有已允收實驗疫苗的兒童樣本資料,並且要確定該組中生病的兒童比例是否與未允收疫苗的組不同。
為了使用雙比例製程,樣本必須相互獨立。
資料描述
大學的財政援助辦公室對其大學生進行調查,確定男生還是女生更可能獲得暑假職業。在抽樣的 802 名男生中,725 人在暑假被僱傭,而抽樣的 712 名女生中有 573 人被僱傭。
雙比例 > 雙比例檢定 - 假設
使用雙比例製程時,您實際上是在根據樣本資料決定哪兩個相反的假設看起來成立:
· H0(原假設):總體比例之間的差異等於選擇的參考值(通常為零)
- 或 -
· H1(備擇假設):總體比例之間的差異不等於選擇的參考值。(預設情況下,H1 是非定向假設。但是,可以指定定向假設。)
輸出範例
樣本 X N 樣本 p
1 725 802
0.903990
2 573 712
0.804775
差異 = p (1) - p (2)
差異估計值: 0.0992147
差異的 95% 信賴區間:
(0.0636706, 0.134759)
差異 = 0(與 ≠ 0) 的檢定: Z =
5.47 P 值 = 0.000
Fisher 精確檢定: P 值 = 0.000
解釋
假定您有男生和女生樣本的僱傭資料,並且要瞭解下列資訊:根據樣本資料,男生被僱傭的比例是否與女生被僱傭的比例相同?換句話說,男生和女生的比例差異是否等於零?因此,您的假設為 H0,差異 = 0 和 H1,差異不等於 0。
雙比例 > 雙比例檢定 - 信賴區間
信賴區間是總體比例之間差異的一系列可能值。由於您不是很確切地知道此差異的實際值,因此可以根據樣本資料透過信賴區間來猜測實際值。樣本比例之間的差異為總體差異提供了估計值。通常,包含總體比例的實際差異的區間的比例等於 1 減去選擇的 a 水準。您可以選擇大於 0% 且小於 100% 的任意 a 水準。常用的 a 水準為 0.05。
輸出範例
樣本 X N 樣本 p
1 725 802
0.903990
2 573 712
0.804775
差異 = p (1) - p (2)
差異估計值: 0.0992147
差異的 95% 信賴區間:
(0.0636706, 0.134759)
差異 = 0(與 ≠ 0) 的檢定: Z =
5.47 P 值 = 0.000
Fisher 精確檢定: P 值 = 0.000
解釋
由於分析學生僱傭資料時使用的 a 水準為 0.05,因此
Minitab 構造了 95% 信賴區間。此區間表明,根據樣本資料,找到暑期工作的男生和女生的總體比例之間的差異介於 0.0636706 和 0.134759 之間的信賴度為 95%。
由於參考值 0 不在信賴區間內,因此可以以 95% 的信賴度否定 H0,並推斷出總體比例不相等。
雙比例 > 雙比例檢定 - 常態近似檢定
雙比例檢定提供兩個統計量,可用來對比例間的差異進行檢定:Z 值 (Z) 和 p 值。Z 值用於確定 p 值。p 值可以指示當 H0 成立時獲得樣本比例之間的差異的可能性。
必須在進行檢定之前確定否定 H0 所需的 p 值。選擇作為標準的值稱為 a 水準。如果 p 值小於或等於 a 水準,則否定 H0 並推斷出總體比例之間的差異不等於參考值。
您可以選擇大於 0% 且小於 100% 的任意 a 水準。常用的 a 水準為 0.05。
如果任一樣本中的事件數少於五,或者任一樣本中的實驗與事件數之差小於五,則對於這些樣本而言,常態近似檢定可能不夠精確。
輸出範例
樣本 X N 樣本 p
1 725 802
0.903990
2 573 712
0.804775
差異 = p (1) - p (2)
差異估計值: 0.0992147
差異的 95% 信賴區間:
(0.0636706, 0.134759)
差異 = 0(與 ≠ 0) 的檢定: Z =
5.47 P 值 = 0.000
Fisher 精確檢定: P 值 = 0.000
解釋
對於學生僱傭資料,Z 為 5.47,關聯的 p 值為 0.000。當 Minitab 顯示
p 值為 0.000 時,表明實際 p 值小於 0.0005。這意味著,當總體比例中的差異實際為 0 時,獲得樣本總體中的差異的機會將小於 0.05%。
雙比例 > 雙比例檢定 -
Fisher 精確檢定
當指定檢定差異為零時 – 換句話說,即原假設假定兩個比例相等時,Minitab 除了執行常態近似檢定之外,還執行 Fisher 精確檢定。此檢定對於全部樣本都有效,而與每個樣本中的事件或試探數無關。
輸出範例
樣本 X N 樣本 p
1 725 802
0.903990
2 573 712
0.804775
差異 = p (1) - p (2)
差異估計值: 0.0992147
差異的 95% 信賴區間:
(0.0636706, 0.134759)
差異 = 0(與 ≠ 0) 的檢定: Z =
5.47 P 值 = 0.000
Fisher 精確檢定: P 值 = 0.000
解釋
對於學生僱傭資料,Fisher 精確檢定計算的 p 值為
0.000。Minitab 將 p 值捨入為三位小數,因此可以斷定實際 p 值小於 0.0005。此 p 值小於常用的 a 水準,因此可以否定原假設,即找到暑期工作的男生和女生的比例相等。
Basic Statistics > Two Proportions > More


假設檢定
假設檢定是統計決策中最常用的方法之一。一般而言,假設檢定是一種假定初始聲明為真,然後使用樣本資料檢定該聲明的製程。通常,初始聲明是指相關的總體參數,如總體平均值 (m)。
假設檢定包含兩個假設:原假設(以 H0 表示)和備擇假設(以 H1 表示)。原假設是初始聲明,且通常使用先前的研究或常識進行指定。備擇假設是可以相信為真實或有望證明為真實的內容。備擇假設有時是指研究假設,並且可以是定向的或非定向的。
假設檢定的決策製程可以基於給定檢定的機率值(p 值)。
· 如果
p 值小於或等於預先確定的顯著性水準(a 水準),則否定原假設,轉而支援另一個假設。
· 如果
p 值大於 a 水準,則不能否定原假設,且不聲明支援備擇假設。
執行假設檢定時,有四種可能的結果。結果取決於原假設的真假以及能否否定原假設。下表中匯總了這些結果:

如果原假設為真,但否定了原假設,則發生類型 I 錯誤。發生類型 I 錯誤的機率稱為阿爾法 (a),有時也稱為顯著性水準。
如果原假設為假,但未能否定它,則發生類型 II 錯誤。發生類型 II 錯誤的機率稱為 b。
原假設為假時,否定它的機率等於 1 - b。此值也稱為檢定的檢定力。
信賴區間和範圍
信賴區間 (CI) 是用於從樣本資料中估計總體參數的區間。如果備擇假設 (H1) 是非定向的,則 Minitab 同時顯示區間的上下限,如果 H1 是定向的,則只顯示一個邊界。
信賴區間由兩個基本部分構成:
·
點估計 - 從樣本資料中計算的個別值值。此值被認為是相關參數的估計值,但點估計不可能與參數相等。因此,為了考慮估計錯誤的機率,在信賴區間中包含了錯誤邊際,以提供可能的參數值的範圍。
· 錯誤邊際-透過使用機率來確定信賴區間的寬度。為了構造信賴區間,只需從點估計中加上和/或減去錯誤邊際。
對於 a 0.05,構造 95% 的信賴區間。這意味著,用於構造區間的方法產生包含相關參數的區間的機率為 0.95(即 1 - a)。因此,如果構造 100 個 95% 的信賴區間,則大約有 95 個區間包含該參數。換句話說,參數值位於該區間內的機率為 95%。
如果備擇假設有方向,則信賴區間會在一個方向無限延伸。在此情況下,只顯示一個邊界。範例,如果執行 a 為 0.05 單樣本 t 檢定,並且 H1 為 m < 5,將顯示
95% 上限。m 的真實值小於或等於上限的信賴度為 95%。
假設檢定和信賴區間的關係
假設您正在執行假設檢定。回想一下,否定原假設 (H0) 或無法否定該假設的決策可以基於 p 值和您選擇的顯著性水準(a 水準)。如果 p 值小於或等於 a,則否定 H0;如果 p 值大於 a,則無法否定 H0。
如果不使用 p 的合併估計值,那麼您的決策也可以基於使用相同 a 水準構造的信賴區間(或邊界)。範例,顯著性水準為 0.05 的檢定的決策可以基於 95% 信賴區間:
· 如果在 H0 中指定的參考值位於區間之外(即小於下限或大於上限),則可否定 H0。
· 如果在
H0 中指定的參考值位於區間之內(即不小於下限或大於上限),則無法否定 H0。
選擇 a 水準
對 a 的選擇決定類型 I 錯誤的機率。此值越小,錯誤地否定原假設 (H0) 的幾率就越小。但是,a 值越小就意味著檢定力越低,並因此降低了檢測到效應(如果存在)的幾率。
按照慣例,最常用的 a 水準為 0.05。a = 0.05
表示發現實際並不存在的效應的幾率僅為 5%。大多數情況下,認為這種出現錯誤的機率可允收。但是,對特定檢定選擇 a 時,可能需要考慮何種錯誤更嚴重:發現實際不存在的效應,或未發現實際存在的效應。
選擇較小的 a。有時選擇較小、較保守的 a 值更好。範例,假設要檢定新銑床中的樣本,並嘗試決定是否購買並在加工車間中安裝一批這種機器。如果新機器比當前使用的機器更精確,則會節省大量資金,因為生產的殘次品將會減少。但是,購買和安裝一批機器的成本非常高。購買前需要確信新機器更加精確。這種情況下,可能需要選擇較低的 a 值,如 0.001。這樣,如果實際上並非如此,將斷定新機器更精確的幾率也僅為 0.1%。
選擇較大的 a。另一方面,有時選擇較大、較寬鬆的 a 值更好。範例,假設噴氣發動機製造商要檢定一種價格較低的新滾珠軸承的穩定性。很明顯,如果滾珠不合格,則節省的少量滾珠成本沒有潛在災難性後果的代價值得重視。因此,可能需要選擇較高的 a 值,如 0.1。儘管這意味著在不存在差異的情況下將更可能錯誤地斷定存在差異,但更重要的是更可能檢測到軸承穩定性中的差異(如果存在)。
詳細資訊請到官方網站進一步了解: http://www.minitab.com.tw/
和 http://www.minitab.com/
聲明: 本文純粹學術性研討, 內容所提及任何關於 Minitab 專有創作文字, 圖像與架構…等皆屬Minitab Inc. 版權所有, 嚴禁商業上轉貼使用.
沒有留言:
張貼留言