有學過6
sigma的同學, 一定知道 Minitab這套軟體, 因為它把6 sigma實用化了. 過去 Minitab 並沒有中文版, 但對岸有人將它漢化後, 官方也出簡體中文版, 使用簡體中文版會比英文版更friendly, 但畢竟兩岸語文還是有差異, 尤其專有名詞上的差異更讓人難以適從, 例如常態分配 v.s. 正态分布; 品質 v.s. 质量; 巨集 v.s. 宏; 變異數分析
v.s.方差分析; 進階 v.s. 高级…
官方目前沒有繁體中文版.~可惜! 希望 Minitab TWN公司能早日完成繁體中文版的 Minitab. ~期待!
先前談到 Tutorials 教學課程, 了解如何使用 Minitab 各項功能。而在Help 協助 > StatGuide 統計指南中, 則對於輸出的結果有詳細的解釋說明:

Regression > General Regression


廣義迴歸 > 匯總
廣義迴歸用於調查反應 (Y) 和預測變數 (X) 之間的關係,並對其建模。反應必須連續的,但是預測變數可以是連續變數,也可以是類別變數。使用廣義迴歸既可以對線性關係建模,也可以對多項式關係建模。
特別是,迴歸分析經常用於下列方面:
· 確定反應變數如何隨特定預測變數的變化而變化
· 預測任何預測變數值或預測變數值組合的反應變數值
資料描述
某製藥公司希望對科研人員的薪水與其性別、工作年限以及所發表文章的品質指數之間的關係進行建模。該公司希望對全部預測變數間的相互作用進行檢定。
資料:
研究人員薪金.MTW (在樣本資料檔案夾中)
廣義迴歸 > 迴歸表 - 方程式
迴歸方程式是迴歸線的一種代數表示形式,用於描述反應和預測變數之間的關係。迴歸方程式採取的形式為:
反應 = 常數 + 係數 * 預測變數 + …+ 係數 * 預測變數
或者 y = bo + b1X1 + b2X2 + ...+ bkXk
其中:
· 反應
(Y) 是反應的值。
· 常數
(bo) 是當預測變數為零時反應變數的值。由於此常數確定迴歸線截取 Y 軸(相交)的位置,因此它也稱為截距。
· 預測變數 (X) 是預測變數的值。預測變數可以是一個多項式的項。
· 係數(b1,b2,...,bk)表示預測變數值的每個單位變化所對應的平均值反應的估計變化。也就是說,它是 X 增加一個單位時 Y 發生的變化。
Minitab 為模型中每個類別預測變數的每個水準都提供了一個獨立的迴歸方程式。
輸出範例
迴歸方程式
性別
女 薪金 =
39.9669 + 4.17447 文章品質 + 3.68777 年數 - 0.293194 文章品質*年
數
男 薪金 =
43.6179 + 4.50745 文章品質 + 2.60465 年數 - 0.18553 文章品質*年
數
解釋
對於薪金資料,反應變數為薪金,預測變數為「發表的文章」、「年限」、「性別」、「發表的文章 * 年限」、「發表的文章 * 性別」、「年限 * 性別」以及「發表的文章 * 年限
* 性別」。Minitab 顯示一個獨立的迴歸方程式,該方程式僅包含每個水準的性別類別變數的連續預測變數。用於女性的迴歸方程式將按如下方式估計:
薪金 = 39.9669 + 4.17447 發表的文章 + 3.68777 年限 - 0.293194 發表的文章 * 年限
用於男性的迴歸方程式將按如下方式估計:
薪金 = 43.6179 + 4.50745 發表的文章 + 2.60465 年限 - 0.18553 發表的文章 * 年限
您可以將每個斜率值解釋為預測變數增加 1 時的薪金變化。範例,對於女性而言,當發表的文章品質增加一個單位時,薪金將增加
4.17447。
您可以將每個截距值解釋為每個預測變數為零時的薪金預測值。範例,對於男性而言,如果每個預測變數都為零,則薪金為 43.6179(或 43,617.90 美元)。
廣義迴歸 > 迴歸表 - 係數
係數表欄出了預測變數的估計係數。線性迴歸用於檢查反應和預測變數之間的關係。要確定反應和預測變數之間觀測到的關係是否統計意義顯著,需要:
· 確定係數 p 值:P 的係數值(p 值)描述反應和預測變數之間的相關性是否統計意義顯著。
· 將係數 p 值與您的 a 水準進行比較:如果
p 值小於您已選擇的 a 水準,則相關性的統計意義顯著。常用的
a 水準為 0.05。
輸出範例
係數
項 係數 係數標準誤差 T P
常數 41.7924 4.25522
9.82143 0.000
性別
女 -1.8255 4.25522
-0.42900 0.671
文章品質 4.3410 0.84524
5.13575 0.000
年數 3.1462 0.47962
6.55980 0.000
性別*文章品質
女 -0.1665 0.84524
-0.19698 0.845
性別*年數
女 0.5416 0.47962
1.12915 0.269
文章品質*年數
-0.2394 0.07823 -3.05984
0.005
性別*文章品質*年數
女 -0.0538 0.07823
-0.68815 0.497
解釋
對於薪金資料,結果可以匯總如下:
· 性別不是主要的係數 (P = 0.671),也不與其他任何預測變數有顯著的交互作用。
· 發表的文章是一個顯著的係數 (P = 0.000)。
· 年限是一個顯著的係數 (P = 0.000)。
· 發表的文章與年限之間的交互作用非常顯著 (P = 0.005)。這一交互作用表明,這兩個預測變數中的任一變數對薪金的效應取決於另一個預測變數的水準。
廣義迴歸 > 迴歸表 - 模型匯總
S、R 和調整的 R 是模型對資料的適合度的量測。這些值有助於您選擇具有最佳適配的模型。
· S 以反應變數的單位進行量測,它表示資料值偏離迴歸線的標準距離。對於給定研究,等式預測反應的效果越好,S 越小。
· R(R
平方)描述在觀測的反應值中由預測變數解釋的變異量。R 始終隨預測變數的增加而增大。範例,最佳的五預測變數模型的 R 始終比最佳的四預測變數模型的高。因此,比較相同大小的模型時 R 最有效。
· 調整的 R 表示已根據模型中的項數調整的修正 R。如果包含了不必要的項,R 會人為地變得很高。與 R 不同,調整的 R 在您向模型中增加項時可能變小。使用調整的 R 比較預測變數數不同的各個模型。
沖床和 R(預測的)可用於量測模型對反應的預測好壞程度。
· PRESS 是預測誤差的平方和。一般而言,PRESS
值越小,模型的預測能力就越好。PRESS 用於計算預測的 R。
· R(預測的)表示模型對新觀測值預測反應的好壞程度。預測的 R 可以防止過度適配模型。在比較模型方面,這個統計值比調整的 R 更有用,因為它是用模型計算中未包含的觀測值計算得出的。較大的預測的 R 值描述模型的預測能力較強。
輸出範例
模型匯總
S = 3.99399 R-Sq = 92.95% R-Sq(調整) = 91.12%
PRESS = 880.182 R-Sq(預測) =
85.59%
解釋
此模型可以解釋薪金中 92.95% 的變異。調整的 R 為
91.12%。R(預測的)為 85.59%,表示在將模型用於預測時,模型可以解釋薪金中 85.59% 的變異。
廣義迴歸 > 變異數分析表 -
P 值
變異數分析表顯示反應資料中由預測變數解釋的變異量以及剩餘未解釋的變異量。
p 值是應該考慮的最為重要的結果。使用 p 值分析迴歸係數是否顯著不同於 0。如果 p 值小於預先選擇的 a 水準,則可以推斷至少有一個係數不為零。常用的 a 水準為 0.05。
輸出範例
變異數分析
來源 自由度 Seq SS Adj SS
Adj MS F P
迴歸 7 5677.93
5677.93 811.132 50.8486
0.000000
性別 1 614.44
2.94 2.936 0.1840
0.671324
文章品質 1
2949.32 420.75 420.747
26.3759 0.000021
年數 1 1923.48
686.43 686.427 43.0310
0.000000
性別*文章品質 1 5.38
0.62 0.619 0.0388
0.845322
性別*年數 1 25.07
20.34 20.338 1.2750
0.268769
文章品質*年數 1 152.69
149.35 149.352 9.3626
0.004959
性別*文章品質*年數
1 7.55 7.55
7.554 0.4736 0.497229
誤差 27 430.70
430.70 15.952
合計 34 6108.63
解釋
迴歸的 P 值為 0.000,表示至少有一個迴歸係數顯著不同於零。發表的文章 * 年限的交互係數 (P = 0.004959) 、發表的文章 (P = 0.000021) 和年限 (0.000000) 的係數都是顯著的。
廣義迴歸 > 異常觀測值表 - 標準化殘差
異常觀測表顯示帶有絕對值大於 2 的標準化殘差的案例。這些案例不那麼遵循建議的迴歸方程式。
對於異常觀測值,應調查資料記錄是否正確,資料收集製程是否受到其他因素的影響。
輸出範例
異常觀測值的適配和診斷
適配
觀測值 薪金 適配 標準誤差 殘差 標準化殘差
2 77.3
85.7211 2.74590 -8.42106
-2.90348 R
5 87.7
79.8734 1.09710 7.82658
2.03799 R
R 表示此觀測值含有大的標準化殘差
解釋
對於薪金資料,兩個觀測值 2 和 5 都有絕對值大於 2(-2.90348 和 2.03799)的標準化殘差。這兩個觀測值不那麼遵循建議的迴歸方程式。
注意
殘差圖也有助於檢查有關迴歸模型的假設。
廣義迴歸 > 預測值 - 預測變數的值
要求計算反應的平均值或預測新反應值時,Minitab 顯示預測變數的所選值。
輸出範例
新觀測值的預測值
新觀 適配
測值 適配 標準誤差 95% 信賴區間 95% 預測區間
1 71.9482
1.38346 (69.1096, 74.7868) (63.2755, 80.6209)
新觀測值的自變數值
新觀 文章
測值 品質 年數 性別
1 5
5 女
解釋
對於薪金資料,Minitab 預測了在下列預測值組合下的薪金(反應)的平均值:發表的文章為 5,年限為 5,性別為 F。
廣義迴歸 > 預測值 - 預測值
要求計算預測變數的某些設定下的反應的平均值或預測新反應值時,Minitab 顯示預測值表。適配是指在所要求的預測變數設定的組合下反應的預測(適配)值。
輸出範例
新觀測值的預測值
新觀 適配
測值 適配 標準誤差 95% 信賴區間 95% 預測區間
1 71.9482
1.38346 (69.1096, 74.7868) (63.2755, 80.6209)
新觀測值的自變數值
新觀 文章
測值 品質 年數 性別
1 5
5 女
解釋
關於薪金資料,Minitab 預測薪金的平均值,對於發表的文章為 5,對於年限為 5,對於性別為 F。使用估計的迴歸方程式,Minitab 計算薪金的可預測(適配)平均值為 71.9482(71,948.20 美元),標準差為 1.38346(1,383.46 美元)。
廣義迴歸 > 預測值 - 預測區間
對於新反應預測,預測區間是期望新反應值所落的範圍。也就是說,預測區間提供了給定預測變數水準的組合下可能的反應值的區間。
輸出範例
新觀測值的預測值
新觀 適配
測值 適配 標準誤差 95% 信賴區間 95% 預測區間
1 71.9482
1.38346 (69.1096, 74.7868) (63.2755, 80.6209)
新觀測值的自變數值
新觀 文章
測值 品質 年數 性別
1 5
5 女
解釋
有關女性薪金資料,您可以 95% 的信賴度估計其預測薪金介於 63,277.50 美元和 80,620.90 美元 之間,發表的文章品質指數為 5,年限為 5 年。
廣義迴歸 > 圖表 - 殘差的直方圖
殘差的直方圖顯示全部觀測值的殘差異布。使用直方圖作為研究工具來瞭解資料的下列特徵:
· 典型值、波動或變異以及形狀
· 資料中的異常值
殘差的直方圖應該為鍾形。使用此圖尋找下列資訊:
此圖表趨勢... 表明...
長尾 偏斜度
遠離其他長條的長條 異常值
由於直方圖的外觀會根據用於對資料進行分組的區間數而變更,因此請使用常態機率圖和適合度檢定來評定殘差是否為常態。
輸出範例

解釋
對於薪金資料,直方圖不呈常態曲線分布。評估常態機率圖以評估殘差是否呈常態分布。
廣義迴歸 > 圖表 - 殘差的常態機率圖
此圖表圖示當分布為常態時的殘差及其期望值。根據分析得出的殘差應該是常態分布的。實際上,對於具有大量觀測值的資料,略微偏離常態性不會嚴重影響結果。
殘差的常態機率圖應該大致為一條直線。使用此圖尋找下列資訊:
此圖表趨勢... 表明...
非直線 非常態性
尾部為曲線 偏斜度
遠離直線的點 異常值
斜率不斷變化 未確定的變數
如果資料的觀測值不足 50 個,則即使殘差是常態分布的,圖也可能在尾部顯示曲率。隨著觀測值數的減少,機率圖甚至可能會顯示更大的變異和非線性。使用常態機率圖和適合度檢定來評定小資料集中殘差的常態性。
如果資料不呈常態分布,您可能希望考慮使用 Box-Cox 轉換來轉換資料。
輸出範例

解釋
對於薪金資料,殘差顯示為直線。沒有證據表明存在非常態性、偏斜度、異常值或未確定的變數。
廣義迴歸 > 圖表 - 殘差與適配
此圖表圖示殘差與適配。殘差應該在 0 附近隨機分散。使用此圖尋找下列資訊:
此圖表趨勢... 表明...
殘差相對適配呈扇形或不均勻分散 異變異數
曲線 缺少高次項
遠離 0 的點 異常值
在 x 方向遠離其他點的點 有影響的點
輸出範例

解釋
對於薪金資料,殘差隨機分散在 0 附近。沒有證據表明存在異變異數、缺項、異常值或有影響的點。
廣義迴歸 > 圖表 - 殘差與順序
此圖表以相應觀測值的順序圖示殘差。觀測值的順序可能影響結果時此圖會很有用,以時間順序或以某些其他順序(如地理區域)採集資料時可能影響結果。此圖在試驗未被隨機化的設計實驗中尤其有協助。
圖中的殘差應該在中心線附近隨機波動。檢查此圖以檢視相鄰誤差項之間是否存在任何相關性。殘差之間的相關性可以表示為:
· 殘差中的上升或下降趨勢
· 相鄰殘差的符號快速變化
輸出範例

解釋
對於薪金資料,殘差隨機分散在 0 附近。沒有證據表明誤差項彼此相關。
廣義迴歸 > 圖表 - 殘差與變數
此圖表圖示殘差與其他變數。殘差應該在中心線附近隨機波動。如果變數已經包含在模型中,則請使用此圖確定是否應該增加該變數的高次項。如果變數尚未包含在模型中,則請使用此圖確定變數是否系統地影響反應。
使用此圖尋找下列資訊:
此圖表趨勢... 表明...
殘差排欄成圖表趨勢 變數正在系統地影響反應
點的排欄有曲率 應該在模型中包含變數的高次項
輸出範例

解釋
對於薪金資料,對應殘差來描繪預測年限。此描繪圖顯示了一些曲率。您可能希望在
迴歸方程式中增加高次項。
廣義迴歸 > 圖表 - 四合一殘差圖
四合一殘差圖在一個圖表視窗中同時顯示四種不同的殘差圖。此版面有助於比較這些圖以確定模型是否符合分析的假設。此圖表中的殘差圖包含:
· 直方圖 - 表明資料是否偏斜或資料中是否存在異常值
· 常態機率圖 - 表明資料是否為常態分布的、其他變數是否影響反應或資料中是否存在異常值
· 殘差與適配 - 表明變異數是否恆定、是否存在非線性關係或資料中是否存在異常值
· 殘差與資料順序 - 表明資料中是否存在因時間或資料採集順序而產生的系統化影響
輸出範例

解釋
要檢視四合一圖中每個殘差圖的解釋,請參考本主題之前每種殘差圖的個別值主題。
Regression > General Regression > more


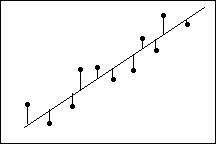
什麼是簡單線性迴歸?
簡單線性迴歸檢查兩個連續變數之間的線性關係:一個反應 (y) 和一個預測變數 (x)。當這兩個變數相關時,可以從幾率準確性更好的預測變數值預測出反應值。
迴歸提供「最佳」適配資料的線。然後可以使用此直線來:
· 檢查反應變數如何隨預測變數的變化而變化
· 預測任一預測變數 (x) 的反應變數值 (y)
用於繪製此「最佳線」的方法稱為最小平方標準。最小平方標準要求最佳適配迴歸線是一條誤差項(點到線的距離)平方和最小的線。
什麼是多元線性迴歸?
多元線性迴歸檢查一個連續反應與兩個或更多個預測變數之間的線性關係。
如果預測變數的數量很大,則在用全部預測變數適配迴歸模型之前,應使用逐步或最佳子集模型選擇技術篩除與反應無關的預測變數。
什麼是殘差?
Minitab 計算三種類型的殘差:
· 常規殘差:觀測值 - 預測值。
· 標準化殘差:常規殘差/常規殘差的標準差。標準化消除了位置對於預測變數空間中資料點的影響。
· 學習化已刪除殘差:對於第 i 個資料點,遵循與標準化殘差相同的表達方式。但是,計算第 i 個 學習化已刪除殘差時適配和標準差都是在刪除第 i 個觀測後得到的。與標準化殘差相比,學習化已刪除殘差在出現異常資料點時會變大。
什麼是統計顯著性?
如果研究的結果比僅由幾率所預期的更「異常」,則描述這些結果的統計意義顯著。範例,假設總體的平均值為 30,而該總體中的一個樣本產生了 35 的平均值。如果樣本平均值不是隨機現象的結果,而是總體平均值大於 30 這一事實的結果,則樣本平均值的統計意義顯著,從而否定了初始假設。
統計顯著性不同於實際顯著性。結果可能會僅僅因為抽取了過多樣本而被錯認為統計意義顯著。
請考慮上述總體平均值為 30 的範例。假設從該總體中抽取另一個樣本,而該樣本平均值變為 30.5(基於 1000 的樣本大小)。這與平均值實際為 30 這一聲明相違背,因此有可能可以確定此樣本平均值的統計意義顯著。這只是大樣本大小的一個典型結果。
在大多數情況下,我們不能認為 30.5 的樣本平均值是足以斷定總體平均值不是 30 的充分證據。因此,這一結果並無實際意義。
統計意義的顯著性通常由假設檢定中的 p 值來確定。如果 p 值較小(範例,小於 0.05),則該統計量稱為統計意義顯著。
模型假設
迴歸和變異數分析製程關於誤差做出下列假設:
· 誤差為常態分布,且平均值為 0。
· 誤差變異數不會為不同因子水準或根據預測反應的值而發生變更。
· 每種誤差都獨立於全部其他誤差。在所設計的實驗中,獲得獨立誤差的最好方式是隨機化實驗的實驗順序。
在分析中檢定這些假設的有效性。殘差是誤差的最佳估計值。因此,可以使用殘差圖以圖表方式檢查每個假設。
如果模型違反這些假設,則分析的結果可能有誤導性。範例,如果誤差相互關聯,則可能會錯誤地估計係數的標準誤差,從而導致錯誤的 t 值和 p 值。
直方圖和常態性
下列是從常態分布中抽取的九個資料集樣本。這些樣本沒有問題;但是,這些直方圖中大多數看起來不是鍾形,這描述了為什麼不應該使用直方圖來判斷資料的常態性。判斷資料是否為常態分布需要使用常態機率圖。
隨機產生樣本的直方圖

每個樣本包含常態分布中的 24 個觀測值。
非常態性的效應
迴歸和變異數分析的一個假設為殘差來自常態分布。但是,如果設計僅有固定因子,設計為平衡或接近平衡,且具有相當多的觀測值,則略微偏離常態性不會嚴重影響結果。
發現非常態圖表有趨勢時該怎麼做
可能難以正確指出常態機率圖中明顯偏離常態性的原因。可能的原因包含:
· 齊次變異數假設失敗
· 殘差異常大(異常值)
· 模型中缺少重要變數
· 資料來自非常態總體
對於完整分析,請將常態機率圖與其他診斷圖以及適合度統計量結合使用。
如果發現非常態圖表趨勢:
1 使用其他診斷圖檢視非常態性是否由非常態總體中的資料之外的因素所導致。
2 使用統計 > 基本統計 > 常態性檢定來執行常態性檢定。
3 如果確定資料來自非常態總體,則可以在繼續分析之前轉換資料。請參見轉換反應變數。
注意
修復不等變異數問題的轉換通常也修復常態性問題。
轉換反應變數
殘差表示異變異數或非常態性時,必須進行轉換。
您可能還會發現在模型表現出顯著缺適性時資料轉換非常有用,而且這種轉換在反應曲面實驗的分析中尤為重要。假設在模型中包含全部顯著的交互作用和二次項,但缺適性檢定表明需要高次項。轉換可以消除缺適性。
如果資料轉換修正了此問題,使用迴歸分析比用其他可能更複雜的分析方法要好一些。迴歸分析或實驗設計分析的結果可以指導我們選擇合適的資料轉換方法解決不同的問題。
Box-Cox 轉換是最常用的變異數穩定轉換。在下面第一個圖表中,殘差表示異變異數。第二個圖表顯示變異數穩定轉換之後的殘差。適配的刻度(x 軸)變更,而變異數變為恆定。
未轉換資料
已轉換資料

常態機率圖中的圖表趨勢
下列圖表趨勢違反了誤差為常態分布這一假設。

S 曲線表示長尾分布。 反向 S 曲線表示短尾分布。

上凸曲線表示非對稱分布。 遠離線的幾個點表示分布中有異常值。
殘差與適配圖中的圖表趨勢
下列圖表趨勢顯示異常值和對誤差為恆定這一假設的衝突。
異常值圖
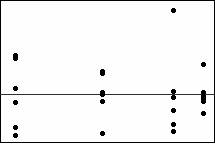
右上角的殘差比圖中其他全部都大很多,因此為異常值。如果異常值過多,則模型可能不妥當。異常值可能是由於量測錯誤所導致。應該調查異常值以確定其原因。
異變異數圖

殘差的變異數隨適配增加。請注意,隨著適配的增加,殘差在零殘差線周圍分散得更廣,指明不等的(非恆定)變異數。此圖表趨勢表明誤差變異數隨平均值的增加而增加。資料的轉換會有助於穩定這些變異數。
發現圖表有趨勢時該怎麼做
如果圖顯示... 執行此操作...
異變異數 1
使用統計 > 變異數分析 > 變異數相等檢定來檢定相等變異數的假設。
2 如果圖或檢定表明變異數不等,則考慮轉換反應變數。
異常值或有影響的點 1 驗證觀測值不是量測或資料錄入錯誤。
2 考慮執行分析時不包含此觀測值來檢視它是否影響結果。
缺少高次項 增加此項並重新適配模型。
殘差與順序圖中的圖表趨勢
下列圖表趨勢違反了誤差彼此獨立這一假設。

隨著觀測值的順序從左到右提高,殘差系統地降低。

殘差的值從低(左)到高(右)急劇變化。
發現圖表有趨勢時該怎麼做
殘差與資料順序圖中的圖表趨勢表明誤差不是獨立的。此指示可能嚴重影響分析的結論,因此應該至少考慮下列一種補救措施:
· 由於誤差的非獨立性往往難以修正,因此如果要進行設計的實驗,應該盡量透過隨機化試驗以防止出現這種問題。
· 向模型中增加時間效應以消除誤差項的相關。範例,正在檢視幾個月期間的日收入。增加表示一周中某天的因子會消除誤差項中的非獨立性。
· 考慮時間序列製程(如 ARIMA)以解決誤差項中的自相關。
發現圖表有趨勢時該怎麼做
殘差與變數圖中的圖表趨勢表明可能未在模型中包含重要變數或未包含變數的高次項。
· 如果該變數在模型中,請為該變數增加高次項並重新適配模型。範例,曲線圖表趨勢表明應該增加平方項。
· 如果該變數不在模型中,請為該變數增加一項並重新適配模型。
詳細資訊請到官方網站進一步了解: http://www.minitab.com.tw/
和 http://www.minitab.com/
聲明: 本文純粹學術性研討, 內容所提及任何關於 Minitab 專有創作文字, 圖像與架構…等皆屬Minitab Inc. 版權所有, 嚴禁商業上轉貼使用.
沒有留言:
張貼留言