有學過6
sigma的同學, 一定知道 Minitab這套軟體, 因為它把6 sigma實用化了. 過去 Minitab 並沒有中文版, 但對岸有人將它漢化後, 官方也出簡體中文版, 使用簡體中文版會比英文版更friendly, 但畢竟兩岸語文還是有差異, 尤其專有名詞上的差異更讓人難以適從, 例如常態分配 v.s. 正态分布; 品質 v.s. 质量; 巨集 v.s. 宏; 變異數分析
v.s.方差分析; 進階 v.s. 高级…
官方目前沒有繁體中文版.~可惜! 希望 Minitab TWN公司能早日完成繁體中文版的 Minitab. ~期待!
先前談到 Tutorials 教學課程, 了解如何使用 Minitab 各項功能。而在Help 協助 > StatGuide 統計指南中, 則對於輸出的結果有詳細的解釋說明:

Regression > Ordinal Logistic Regression
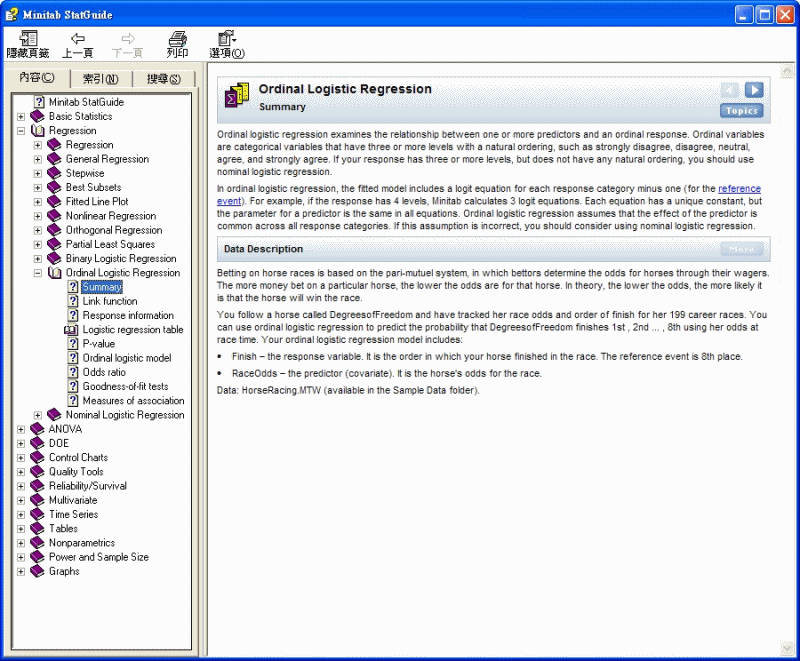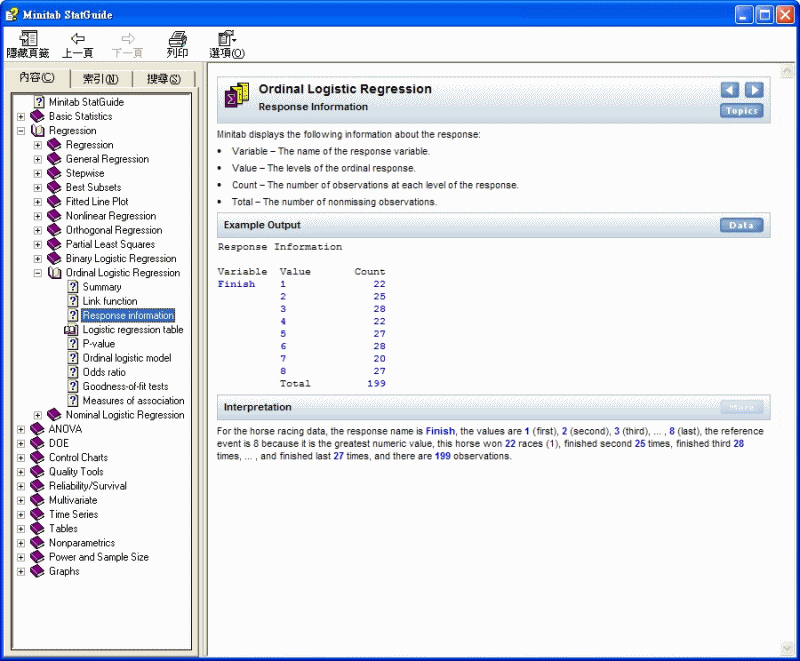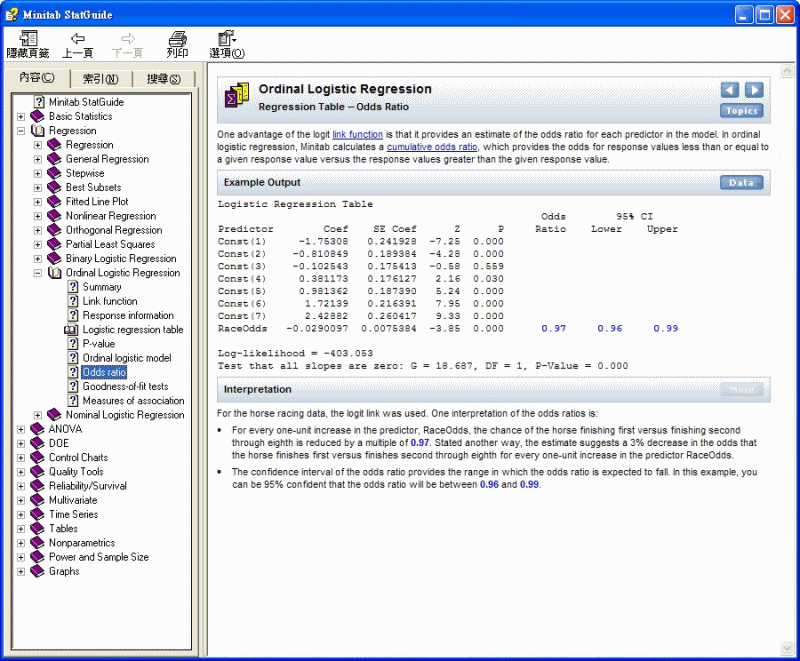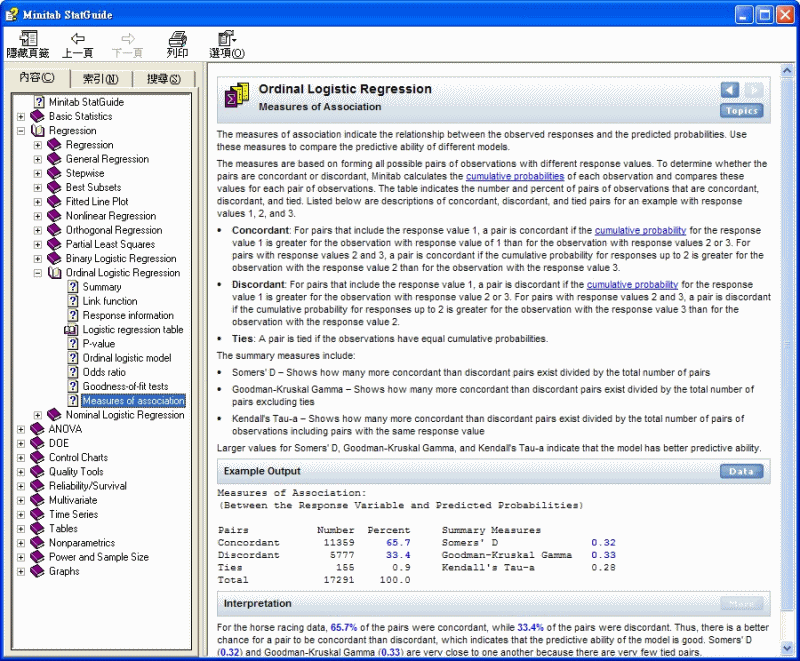

序數邏輯斯迴歸 > 匯總
序數邏輯斯迴歸檢查一個或多個預測變數和一個順序反應之間的關係。順序變數是擁有三個或更多具有自然順序的可能水準的類別變數,範例非常不同意,不同意,中立,同意,非常同意。如果反應有三個或更多水準但不具有任何自然順序,應該使用名義邏輯斯迴歸。
在序數邏輯斯迴歸中,適配模型包含每個反應類別(剔除對應於參考事件的反應類別)的 logit 方程式。範例,如果反應具有 4 個水準,Minitab 將計算 3 個
logit 方程式。每個方程式都有一個唯一的常數,但是全部的方程式中某個預測變數的參數是相同的。序數邏輯斯迴歸假設該預測變數在全部的反應類別上具有公共效應。如果該假設不成立,應該考慮使用名義邏輯斯迴歸。
資料描述
賭馬現列的基礎是同注分彩體制,在此體制中賭家透過馬身上的賭注來確定其賭注比例。特定的一匹馬身上的賭金越多,它的賭注比例越低。理論上,賭注比例越低,馬贏得比賽的可能性越大。
您關心一匹名為 DegreesofFreedom 的馬,並且軌跡了她在 199 場職業比賽中的比賽賭注比例和名次。可以使用序數邏輯斯迴歸來根據她比賽時的賭注比例來預測 DegreesofFreedom 取得第 1 名、第 2 名 ...,第 8 名的機率。序數邏輯斯迴歸模型包含:
· Finish - 反應變數。它表示您的馬在比賽中取得的名次。參考事件是第 8 名。
· RaceOdds - 預測變數(共變異數)。它表示這匹馬在比賽中的賭注比例。
資料:
賽馬.MTW (在樣本資料檔案夾中)
序數邏輯斯迴歸 > 連結函數
Minitab 提供了三個連結函數,使用這些函數,您可以適配順序反應模型的主要類。它們是累積標準邏輯斯分布函數 (logit) 的反函數、累積標準常態分布函數 (normit) 的反函數和 Gompertz 分布函數 (gompit) 的反函數。
您想要選擇可以良好適配資料的連結函數。可以使用適合度統計量來比較使用不同連結函數的模型適配。可能會因為歷史原因或因為它們具有特殊的學科意義而使用特定的連結函數。
Logit 連結函數的一個優勢就是它可以提供模型中的每個預測變數的優勢比的估計值。
輸出範例
連結函數:Logit
解釋
對於賽馬資料,調查人員選擇了使用 Logit 連結函數。
序數邏輯斯迴歸 > 反應資訊
Minitab 顯示了反應的下列資訊:
· 變數
- 反應變數的名稱。
· 值
- 順序反應的水準。
· 計數
- 每個反應水準上的觀測值數。
· 合計 - 非遺失觀測值數。
輸出範例
反應資訊
變數 值 計數
結束 1 22
2 25
3 28
4 22
5 27
6 28
7 20
8 27
合計 199
解釋
對於賽馬資料,反應名為 Finish,值為 1(第一名),2(第二名),3(第三名),..., 8(最後一名),參考事件為 8(因為它是最大值),這匹馬 22 次贏得比賽(第一名),25 次為第二名,28 次取得第三名,...,27 次取得最後一名,有 199 個觀測值。
序數邏輯斯迴歸 > 邏輯斯迴歸表
- P 值
P 值描述觀測的關係是否統計意義顯著。您需要:
1 找到位於迴歸表下的 p 值。透過檢定是否全部的參數都等於 0,p 值描述是否至少一個預測變數和反應之間存在顯著相關性。
2 將此 p 值與您的 a 水準進行比較。常用的 a 水準為
0.05。
- 如果 p 值小於或等於 a 水準,那麼相關性顯著,並且可以斷定至少一個預測變數與反應顯著關聯。
- 如果 p 值大於 a 水準,那麼可以斷定不存在顯著關聯,並且解釋結束。
3 如果在步階 2 中斷定至少有一個顯著的預測變數,請識別出模型中每一項的 p 值。這些 p 值描述特定的預測變數和順序反應之間是否存在統計意義顯著相關性。
4 將這些 p 值逐個與您的 a 水準進行比較:如果 p 值小於或等於所選擇的 a 水準,那麼關聯是顯著的。
輸出範例
邏輯斯
迴歸表
95% 信賴區
間
自變數 係數 係數標準誤差 Z P 優勢比 下限 上限
常數(1) -1.75308 0.241928
-7.25 0.000
常數(2) -0.810849 0.189384
-4.28 0.000
常數(3) -0.102543 0.175413 -0.58
0.559
常數(4) 0.381173 0.176127
2.16 0.030
常數(5) 0.981362 0.187390
5.24 0.000
常數(6) 1.72139 0.216391
7.95 0.000
常數(7) 2.42882 0.260417
9.33 0.000
名次 -0.0290097 0.0075384
-3.85 0.000 0.97
0.96 0.99
對數概度 = -403.053
檢定全部斜率是否為零:G = 18.687,DF = 1,P
值 = 0.000
解釋
對於賽馬資料,用於檢定 RaceOdds 的斜率項為零的 p 值等於 0.000。假定 a 水準為 0.05。因為0.000 小於 0.05,可以斷定反應變數 (Finish) 和預測變數 (RaceOdds) 之間存在顯著相關性。
RaceOdds 的 p 值等於用於檢定斜率項為 0 的 p 值。當模型只有一個預測變數時這一點總是成立的。
序數邏輯斯迴歸 > 邏輯斯迴歸表
- 序數邏輯斯模型
序數邏輯斯迴歸檢查一個或多個預測變數和一個順序反應之間的關係。
序數邏輯斯迴歸方程式分別處理每個順序結果。邏輯斯迴歸方程式由多個二元
邏輯斯迴歸方程式構成,分別對應於除去一個之後的每個反應值。全部方程式中與共變異數相關的參數都是相同的。使用此模型檢查當預測變數變更時觀測某特定順序結果的機率的變更情況。
輸出範例
邏輯斯
迴歸表
95% 信賴區
間
自變數 係數 係數標準誤差 Z P 優勢比 下限 上限
常數(1) -1.75308 0.241928
-7.25 0.000
常數(2) -0.810849 0.189384
-4.28 0.000
常數(3) -0.102543 0.175413
-0.58 0.559
常數(4) 0.381173 0.176127
2.16 0.030
常數(5) 0.981362 0.187390
5.24 0.000
常數(6) 1.72139 0.216391
7.95 0.000
常數(7) 2.42882 0.260417
9.33 0.000
名次 -0.0290097 0.0075384
-3.85 0.000 0.97
0.96 0.99
對數概度 = -403.053
檢定全部斜率是否為零:G = 18.687,DF = 1,P
值 = 0.000
解釋
對於賽馬資料,因為反應資訊表中有 8 個值,所以有7個邏輯斯方程式。全部的方程式都會呈現一個 logit 連結。
· 第一個方程式是由邏輯斯迴歸方程式中的 Const(1) 係數 (-1.75308) 和 RaceOdds 係數 (-0.0290097) 構成的。如果給定賭注比例,透過此二元邏輯斯方程式可以得出馬取得第一名的機率。
· 第二個方程式是由邏輯斯迴歸方程式中的 Const(2) 係數 (-0.810849) 和 RaceOdds 係數 (-0.0290097) 構成的。如果給定賭注比例,透過此二元邏輯斯方程式可以得出馬取得第一名或第二名的機率。
· 第三個方程式是由邏輯斯迴歸方程式中的 Const(3) 係數 (-0.102543) 和 RaceOdds 係數 (-0.0290097) 構成的。如果給定賭注比例,透過此二元邏輯斯方程式可以得出馬取得第一名、第二名或第三名的機率。
第四個到第七個方程式的構造和解釋方式與此相同。
RaceOdds 的負係數 (-0.0290097) 表明賭注比例越高馬贏得比賽的機率越低。
序數邏輯斯迴歸 > 迴歸表 - 優勢比
Logit 連結函數的一個優勢就是它可以提供模型中的每個預測變數的優勢比的估計值。在序數邏輯斯迴歸中,Minitab 計算一個累計優勢比,它可以提供反應值小於或等於給定的反應值與反應值大於給定的反應值之間的比例。
輸出範例
邏輯斯
迴歸表
95% 信賴區
間
自變數 係數 係數標準誤差 Z P 優勢比 下限 上限
常數(1) -1.75308 0.241928
-7.25 0.000
常數(2) -0.810849 0.189384
-4.28 0.000
常數(3) -0.102543 0.175413
-0.58 0.559
常數(4) 0.381173 0.176127
2.16 0.030
常數(5) 0.981362 0.187390
5.24 0.000
常數(6) 1.72139 0.216391
7.95 0.000
常數(7) 2.42882 0.260417
9.33 0.000
名次 -0.0290097 0.0075384
-3.85 0.000 0.97
0.96 0.99
對數概度 = -403.053
檢定全部斜率是否為零:G = 18.687,DF = 1,P
值 = 0.000
解釋
對於賽馬資料,使用了 logit 連結。該優勢比的一種解釋為:
· 預測變數 RaceOdds 每增加一個單位,馬取得第一名的幾率與取得第二到第八名的幾率的比例減小
0.97 倍。另一種解釋為:該估計值描述預測變數 RaceOdds 每增加一個單位,馬取得第一名與取得第二名到第八名的幾率減小 3%。
· 優勢比的信賴區間提供預期優勢比將落入的範圍。在此範例中,優勢比將落在 0.96 和 0.99 之間的可信度為
95%。
序數邏輯斯迴歸 > 適合度檢定
適配序數邏輯斯模型時,您想要選擇良好適配資料的模型(連結函數和預測變數)。可以使用適合度統計量來比較不同模型的適配。較低的 p 值表示預測的機率以多項分布無法預測的方式偏離觀測的機率。
Minitab 提供兩種適合度檢定:Pearson 和 Deviance。
Pearson 和 Deviance 是邏輯斯模型的兩種類型的殘差。它們是評估所選模型適配資料的優度的有用量測。P 值越高,模型適配資料的優度越高。您可能想要檢查其他的模型並選擇一個產生最大適合度 p
值的模型(除非某個模型在您的學科中具有特殊意義)。
輸出範例
適合度檢定
方法 卡方 自由度 P
Pearson 929.021 965
0.792
標準差 643.323 965
1.000
解釋
對於賽馬資料來說,Pearson 和 Deviance 檢定的 p 值(分別為 0.792 和
1.000)比 0.05 大很多,這表明沒有足夠的證據證明模型不能很好地適配資料。
序數邏輯斯迴歸 > 相關性量測
相關性量測表明觀測反應和預測機率之間的關係。用這些量測來比較不同模型的預測能力。
這些量測的基礎是形成具有不同反應值的全部可能的觀測值對。要確定對是一致對還是不一致對,Minitab 計算每個觀測值的累積機率並比較每對觀測值的累積機率值。此表描述一致、不一致和結對觀測值對的數量和百分比。下列是以反應值為 1、2 和 3 為例所做的的一致對、不一致對和結對的描述。
· 一致:對於包含反應值 1 的對,如果反應值為 1 的觀測值的反應值 1 累積機率比用反應值為 2 或 3 的觀測值的大,那麼此對為一致對;對於包含反應值 2 和 3 的對,如果反應值為 2 的觀測值的反應達到 2 的累積機率比用反應值為 3 的觀測值的大,那麼此對為一致對。
· 不一致:對於包含反應值 1 的對,如果反應值 1 的累積機率比反應值 2 或 3 的觀測值的大,那麼此對為不一致對;對於包含反應值 2 和 3 的對,如果用反應值為 3 的觀測值的反應達到 2 的累積機率比反應值為 2 觀測值的大,那麼此對為不一致對。
· 結:如果觀測值的累積機率相等,那麼對為結對。
匯總量測包含:
· Somers 的 D - 顯示存在的比不一致對一致的對數除以總對數
· Goodman-Kruskal Gamma - 表示存在的比不一致對一致的對數除以剔除結對的總對數
· Kendall 的 Tau-a - 顯示存在的比不一致對一致的對數除以包含具有相同反應值的對在內的總觀測值對數
Somers 的 D、Goodman-Kruskal Gamma 和 Kendall 的 Tau-a 的值越大,表明模型的預測能力越強。
輸出範例
相關性量測:
(反應變數與預測機率之間)
配對 數量 百分比 量測結果綜述
一致 11359 65.7
Somer 的 D 0.32
不一致 5777 33.4
Goodman-Kruskal Gamma 0.33
結 155 0.9
Kendall 的 Tau-a 0.28
合計 17291 100.0
解釋
對於賽馬資料,65.7% 的對是一致對,33.4% 的對是不一致對。因此,對為一致對的幾率比不一致對的幾率高,表明模型的預測能力較強。因為結對特別少,所以 Somers 的 D (0.32) 和
Goodman-Kruskal Gamma (0.33) 非常接近。
詳細資訊請到官方網站進一步了解: http://www.minitab.com.tw/
和 http://www.minitab.com/
聲明: 本文純粹學術性研討, 內容所提及任何關於 Minitab 專有創作文字, 圖像與架構…等皆屬Minitab Inc. 版權所有, 嚴禁商業上轉貼使用.
沒有留言:
張貼留言