有學過6
sigma的同學, 一定知道 Minitab這套軟體, 因為它把6 sigma實用化了. 過去 Minitab 並沒有中文版, 但對岸有人將它漢化後, 官方也出簡體中文版, 使用簡體中文版會比英文版更friendly, 但畢竟兩岸語文還是有差異, 尤其專有名詞上的差異更讓人難以適從, 例如常態分配 v.s. 正态分布; 品質 v.s. 质量; 巨集 v.s. 宏; 變異數分析
v.s.方差分析; 進階 v.s. 高级…
官方目前沒有繁體中文版.~可惜! 希望 Minitab TWN公司能早日完成繁體中文版的 Minitab. ~期待!
先前談到 Tutorials 教學課程, 了解如何使用 Minitab 各項功能。而在Help 協助 > StatGuide 統計指南中, 則對於輸出的結果有詳細的解釋說明:

Regression > Partial Least Squares


部分最小平方 > 匯總
部分最小平方 (PLS) 是將一組預測變數與多重反應變數產生聯繫的偏迴歸製程。PLS 的設計目的是用於病態資料(預測變數高度相關或數量超過觀測值數)。
PLS 根據 X 和 Y 之間的共變異數將預測變數縮減為一組不相關的分量,然後對這些分量執行最小平方迴歸。PLS 的兩個重要功能包含交叉驗證和預測:
· 使用交叉驗證選擇產生最準確的預測模型的分量數。
· 使用預測評估模型的預測能力或計算新資料的反應。
資料描述
某食品化學實驗室的科學家們分析了 60 種大豆粉的樣本。對於每個樣本,他們測定了濕度和脂肪含量,並記錄了 88 種波長的近紅外 (NIR) 光譜資料。借助 60 個樣本中的 54 個樣本,科學家們使用部分最小平方 (PLS) 估計了反應變數(濕度和脂肪含量)與預測變數(88 種近紅外波長)之間的關係。他們使用其餘的 6 個樣本作為檢定集來評估模型的預測能力。
資料:
大豆.MTW (在樣本資料檔案夾中)
部分最小平方 > 方法表
Minitab 顯示有關用於分析 PLS 模型的方法的資訊。輸出與您用於選擇分量的方法和是否使用了交叉檢定相關。
如果沒有使用交叉驗證,則 Minitab 將顯示:
· 要計算的分量是設定的還是使用者定義的(在指定最大分量數時)。
· 要計算的分量數,預設為 10 或預測變數數兩者中較小的一個。
如果使用交叉驗證,則 Minitab 將顯示:
· 如何執行交叉驗證。
· 要評估的分量是設定的還是使用者定義的(在指定最大分量數時)。
· 要評估的分量數。該數值等於您指定的最大分量數,或在預設情況下,等於 10 個分量或預測變數數兩者中的較小者。
· 交叉驗證根據具有最大預測的 R 平方的模型選擇的分量數。
如果類別預測變數在模型中,則方法表可指定所用編碼類型。
Minitab 選擇的分量構成 PLS 分析和圖中所使用的模型。
輸出範例
方法
交叉驗證 逐一剔除法
要估算的分量 集合
已估算的分量數 10
已選定的分量數 10
解釋
在此範例中,科學家們選擇使用交叉驗證,一次剔除一個觀測值。他們沒有指定要驗證的最大分量數。輸出顯示:
· Minitab 在交叉驗證製程中一次剔除 1 個觀測值。
· Minitab 總共對 10 個分量(預設值)進行了評估。
· Minitab 為 PLS 模型選擇了 10 個分量。
部分最小平方 > 變異數分析表
Minitab 根據所選的模型對每個反應顯示一個變異數分析表。此表顯示反應中由模型解釋的變異量以及剩餘未解釋的變異量。
小於 P(p 值)的值是此表中要考慮的最重要結果。使用 p 值分析迴歸係數是否顯著不同於 0。如果 p 值小於預先選擇的 a 水準,則可以推斷出至少有一個係數不為 0。常用的 a 水準為 0.05。
輸出範例
濕度
的變異數分析
來源 自由度 SS MS
F P
迴歸 10 468.516
46.8516 61.46 0.000
殘差誤差 43
32.777 0.7623
合計 53 501.293
脂肪
的變異數分析
來源 自由度 SS MS
F P
迴歸 10 266.378
26.6378 36.89 0.000
殘差誤差 43 31.050
0.7221
合計 53 297.428
解釋
本例中,Minitab 顯示兩個變異數分析表 - 一個用於濕度,一個用於脂肪含量。兩個反應的
p 值都小於 0.0005,表明模型顯著,且至少有一個迴歸係數不為 0。
部分最小平方 > 預測反應表 -
預測值
可以使用 PLS 模型估計新資料集的反應值,該資料集通常稱為檢定集。Minitab 為每個反應顯示一個預測反應表。
Minitab 為每個新觀測值計算一個預測反應。可以用兩種方式解釋預測反應:
· 解釋為具有一組給定預測變數值的總體中全部觀測值的估計平均值反應
· 解釋為具有一組給定預測變數值的新個別值觀測值的預測反應
兩種解釋的預測反應值相同,但是預測的變異數或精確度不同。這種差異反映在信賴區間和預測區間中,這兩種區間都是預測值預期所要落於的範圍。信賴區間對應於估計的平均值反應,預測區間對應於個別值觀測值的預測反應。預測區間大於信賴區間,因為前者包含較大的不確定性。預測區間不僅包含迴歸參數估計中的不確定性,還包含來自新量測值的不確定性。適配的標準誤差 (SE Fit) 估計一組給定預測變數值的估計平均值反應中的變異。標準誤差越小,估計反應值越精確。
輸出範例
使用
濕度 模型對新觀測值的預測反應
欄 適配 適配標準誤差 95% 信賴區間 95% 預測區間
1
14.5184 0.388841 (13.7343, 15.3026) (12.5910, 16.4459)
2
9.3049 0.372712 ( 8.5532, 10.0565) ( 7.3904, 11.2193)
3
14.1790 0.504606 (13.1614, 15.1966) (12.1454, 16.2127)
4
16.4477 0.559704 (15.3189, 17.5764) (14.3562, 18.5391)
5
15.1872 0.358044 (14.4652, 15.9093) (13.2842, 17.0903)
6
9.4639 0.485613 ( 8.4846, 10.4433) ( 7.4492, 11.4787)
檢定 R-Sq: 0.906451
使用
脂肪 模型對新觀測值的預測反應
欄 適配 適配標準誤差 95% 信賴區間 95% 預測區間
1
18.7372 0.378459 (17.9740, 19.5004) (16.8612, 20.6132)
2
15.3782 0.362762 (14.6466, 16.1098) (13.5149, 17.2415)
3
20.7838 0.491134 (19.7933, 21.7743) (18.8044, 22.7632)
4
14.3684 0.544761 (13.2698, 15.4670) (12.3328, 16.4040)
5
16.6016 0.348485 (15.8988, 17.3044) (14.7494, 18.4538)
6
20.7471 0.472648 (19.7939, 21.7003) (18.7861, 22.7080)
檢定 R-Sq: 0.762701
解釋
在此範例中,檢定集中的新觀測值包含 6 個大豆粉樣本。Minitab 使用
PLS 模型預測這些樣本的反應。第一個大豆粉樣本的濕度的預測反應為 14.5184。如果 14.5184 是估計的平均值反應,則科學家們將使用信賴區間。如果 14.5184 是個別值觀測值的預測反應,則科學家們將使用預測區間。
部分最小平方 > 預測反應表 -
信賴區間
Minitab 為每個預測反應顯示一個信賴區間,提供估計平均值反應預期可以落於的範圍。
輸出範例
使用
濕度 模型對新觀測值的預測反應
欄 適配 適配標準誤差 95% 信賴區間 95% 預測區間
1
14.5184 0.388841 (13.7343, 15.3026) (12.5910, 16.4459)
2
9.3049 0.372712 ( 8.5532, 10.0565) ( 7.3904, 11.2193)
3
14.1790 0.504606 (13.1614, 15.1966) (12.1454, 16.2127)
4
16.4477 0.559704 (15.3189, 17.5764) (14.3562, 18.5391)
5
15.1872 0.358044 (14.4652, 15.9093) (13.2842, 17.0903)
6
9.4639 0.485613 ( 8.4846, 10.4433) ( 7.4492, 11.4787)
檢定 R-Sq: 0.906451
使用
脂肪 模型對新觀測值的預測反應
欄 適配 適配標準誤差 95% 信賴區間 95% 預測區間
1
18.7372 0.378459 (17.9740, 19.5004) (16.8612, 20.6132)
2
15.3782 0.362762 (14.6466, 16.1098) (13.5149, 17.2415)
3
20.7838 0.491134 (19.7933, 21.7743) (18.8044, 22.7632)
4
14.3684 0.544761 (13.2698, 15.4670) (12.3328, 16.4040)
5
16.6016 0.348485 (15.8988, 17.3044) (14.7494, 18.4538)
6
20.7471 0.472648 (19.7939, 21.7003) (18.7861, 22.7080)
檢定 R-Sq: 0.762701
解釋
在此範例中,科學家們要求 95% 的信賴區間。對於第一個樣本種採用該組預測變數值所得到的全部觀測值,其濕度的平均值反應將介於 13.7343 和 15.3026 之間的信賴度為 95%。
部分最小平方 > 預測反應表 -
預測區間
Minitab 為每個預測反應顯示一個預測區間,提供個別值樣本預期要落於的範圍。
預測區間始終比信賴區間寬,這是因為預測個別值反應會涉及更多的不確定性。
輸出範例
使用
濕度 模型對新觀測值的預測反應
欄 適配 適配標準誤差 95% 信賴區間 95% 預測區間
1
14.5184 0.388841 (13.7343, 15.3026) (12.5910, 16.4459)
2
9.3049 0.372712 ( 8.5532, 10.0565) ( 7.3904, 11.2193)
3
14.1790 0.504606 (13.1614, 15.1966) (12.1454, 16.2127)
4
16.4477 0.559704 (15.3189, 17.5764) (14.3562, 18.5391)
5
15.1872 0.358044 (14.4652, 15.9093) (13.2842, 17.0903)
6
9.4639 0.485613 ( 8.4846, 10.4433) ( 7.4492, 11.4787)
檢定 R-Sq: 0.906451
使用
脂肪 模型對新觀測值的預測反應
欄 適配 適配標準誤差 95% 信賴區間 95% 預測區間
1
18.7372 0.378459 (17.9740, 19.5004) (16.8612, 20.6132)
2
15.3782 0.362762 (14.6466, 16.1098) (13.5149, 17.2415)
3
20.7838 0.491134 (19.7933, 21.7743) (18.8044, 22.7632)
4
14.3684 0.544761 (13.2698, 15.4670) (12.3328, 16.4040)
5
16.6016 0.348485 (15.8988, 17.3044) (14.7494, 18.4538)
6
20.7471 0.472648 (19.7939, 21.7003) (18.7861, 22.7080)
檢定 R-Sq: 0.762701
解釋
在此範例中,科學家們要求
95% 的預測區間。對於第一個樣本,濕度的實際反應將介於 12.5910 和 16.4459 之間的信賴度為 95%。
部分最小平方 > 預測反應表 -
檢定 R 平方
只有具有檢定集中觀測值的反應值時,Minitab 才顯示檢定 R 平方。在估計模型的預測能力時,使用檢定 R 來判斷交叉驗證的準確度。如果使用交叉驗證,請比較檢定 R 和預測的 R 平方。理想情況下,這些值應該相近。如果檢定 R 顯著小於預測的 R,則表明交叉驗證對模型的預測能力過於樂觀,或兩個資料樣本來自不同的總體。
輸出範例
使用
濕度 模型對新觀測值的預測反應
欄 適配 適配標準誤差 95% 信賴區間 95% 預測區間
1
14.5184 0.388841 (13.7343, 15.3026) (12.5910, 16.4459)
2
9.3049 0.372712 ( 8.5532, 10.0565) ( 7.3904, 11.2193)
3
14.1790 0.504606 (13.1614, 15.1966) (12.1454, 16.2127)
4
16.4477 0.559704 (15.3189, 17.5764) (14.3562, 18.5391)
5
15.1872 0.358044 (14.4652, 15.9093) (13.2842, 17.0903)
6
9.4639 0.485613 ( 8.4846, 10.4433) ( 7.4492, 11.4787)
檢定 R-Sq: 0.906451
使用
脂肪 模型對新觀測值的預測反應
欄 適配 適配標準誤差 95% 信賴區間 95% 預測區間
1
18.7372 0.378459 (17.9740, 19.5004) (16.8612, 20.6132)
2
15.3782 0.362762 (14.6466, 16.1098) (13.5149, 17.2415)
3
20.7838 0.491134 (19.7933, 21.7743) (18.8044, 22.7632)
4
14.3684 0.544761 (13.2698, 15.4670) (12.3328, 16.4040)
5
16.6016 0.348485 (15.8988, 17.3044) (14.7494, 18.4538)
6
20.7471 0.472648 (19.7939, 21.7003) (18.7861, 22.7080)
檢定 R-Sq: 0.762701
解釋
在此範例中,科學家們採用了新大豆粉樣本的反應資料。
· 對於濕度,檢定 R 為 90.6%。使用 10 分量模型(位於模型選擇和驗證表中)時,濕度的預測 R 為 89.4%。
· 對於脂肪含量,檢定 R 為 76.3%。使用 10 分量模型(位於模型選擇和驗證表中)時,脂肪含量的預測 R 為 78.1%。
由於濕度和脂肪含量的檢定 R 值都非常接近於預測的 R 值,因此科學家們斷定預測和交叉驗證準確地估計了模型的預測能力。
部分最小平方 > 模型選擇和驗證表 - 分量和 X 變異數
Minitab 為模型中的每個反應都顯示模型選擇和驗證表。記號為分量的欄欄出了 Minitab 所計算的模型。第一個模型包含一個分量,第二個模型包含兩個分量,第三個模型包含三個分量,依此類推。每欄都包含 Minitab 所計算的模型的資訊。記號為 X 變異數的列表明預測變數中由模型解釋的變異數數量。
輸出範例
濕度
的模型選擇和驗證
分量 X 變異數 誤差 R-Sq PRESS
R-Sq(預測)
1 0.984976
96.9288 0.806643 103.549
0.793436
2 0.996400
88.9900 0.822479 105.650
0.789245
3 0.997757
71.9304 0.856510 91.172
0.818127
4 0.999427
58.3174 0.883666 75.778
0.848836
5 0.999722
58.1261 0.884048 78.385
0.843634
6 0.999853
48.5236 0.903203 69.024
0.862308
7 0.999963
45.9824 0.908272 71.146
0.858076
8 0.999976
33.1545 0.933862 51.386
0.897493
9 0.999982
32.8074 0.934554 51.055
0.898154
10 0.999986
32.7773 0.934615 53.299
0.893677
脂肪
的模型選擇和驗證
分量 X 變異數 誤差 R-Sq PRESS
R-Sq(預測)
1 0.984976
282.519 0.050127 308.628
0.000000
2 0.996400
229.964 0.226824 267.199
0.101637
3 0.997757
115.951 0.610155 143.986
0.515895
4 0.999427
98.285 0.669550 127.389
0.571698
5 0.999722
57.994 0.805015 76.435
0.743012
6 0.999853
53.097 0.821480 72.109
0.757560
7 0.999963
52.010 0.825133 72.412
0.756540
8 0.999976
48.842 0.835784 76.432
0.743024
9 0.999982
34.344 0.884529 67.884
0.771764
10 0.999986
31.050 0.895604 65.116
0.781068
解釋
在此範例中,科學家們使用了交叉驗證,它為 PLS 模型選擇 10 個分量。由於未指定要交叉驗證的分量數,因此預設情況下,Minitab 驗證了 10 個分量。
具有 10 個分量的模型的 x 變異數值為
0.99,這表明模型實際上解釋了預測變數中的全部變異數。
部分最小平方 > 模型選擇和驗證表 - R 平方
R 平方值提供每個反應中由預測變數解釋的變異的比例,表明每個模型與您的資料的適合度。Minitab 顯示全部計算的模型的 R 值。所選模型的 R 基於變異數分析表中的平方和。
如果不使用交叉驗證,則模型選擇和驗證表中只有 SS 和 R 欄。
輸出範例
濕度
的模型選擇和驗證
分量 X 變異數 誤差 R-Sq PRESS
R-Sq(預測)
1 0.984976
96.9288 0.806643 103.549
0.793436
2 0.996400
88.9900 0.822479 105.650
0.789245
3 0.997757
71.9304 0.856510 91.172
0.818127
4 0.999427
58.3174 0.883666 75.778
0.848836
5 0.999722
58.1261 0.884048 78.385
0.843634
6 0.999853
48.5236 0.903203 69.024
0.862308
7 0.999963
45.9824 0.908272 71.146
0.858076
8 0.999976
33.1545 0.933862 51.386
0.897493
9 0.999982
32.8074 0.934554 51.055
0.898154
10 0.999986
32.7773 0.934615 53.299
0.893677
脂肪
的模型選擇和驗證
分量 X 變異數 誤差 R-Sq PRESS
R-Sq(預測)
1 0.984976
282.519 0.050127 308.628
0.000000
2 0.996400
229.964 0.226824 267.199
0.101637
3 0.997757
115.951 0.610155 143.986
0.515895
4 0.999427
98.285 0.669550 127.389
0.571698
5 0.999722
57.994 0.805015 76.435
0.743012
6 0.999853
53.097 0.821480 72.109
0.757560
7 0.999963
52.010 0.825133 72.412
0.756540
8 0.999976
48.842 0.835784 76.432
0.743024
9 0.999982
34.344 0.884529 67.884
0.771764
10 0.999986
31.050 0.895604 65.116
0.781068
解釋
在此範例中,所選模型的 R 位於具有 10 個分量的欄中。濕度和脂肪含量的 R 分別為 93.5% 和 89.6%,表明模型對資料適配得極好。
部分最小平方 > 模型選擇和驗證表 - R 平方(預測的)
預測的 R 平方值描述每個計算的模型預測反應的優良程度,並且僅在使用交叉驗證時進行計算。Minitab
選擇預測 R 最高的 PLS 模型。
檢查 R 和預測的 R 值來確定由交叉驗證選擇的模型是否最合適。在某些情況下,可以會決定使用由交叉驗證所選擇的模型之外的其他模型。請考慮這樣的範例:向 Minitab 所選擇的模型增加兩個分量會顯著提高 R,而只輕微降低預測的 R。由於預測的 R 只是輕微降低,因此該模型不會過度適配,且可以確定它比較適合您的資料。
輸出範例
濕度
的模型選擇和驗證
分量 X 變異數 誤差 R-Sq PRESS
R-Sq(預測)
1 0.984976
96.9288 0.806643 103.549
0.793436
2 0.996400
88.9900 0.822479 105.650
0.789245
3 0.997757
71.9304 0.856510 91.172
0.818127
4 0.999427
58.3174 0.883666 75.778
0.848836
5 0.999722
58.1261 0.884048 78.385
0.843634
6 0.999853
48.5236 0.903203 69.024
0.862308
7 0.999963
45.9824 0.908272 71.146
0.858076
8 0.999976
33.1545 0.933862 51.386
0.897493
9 0.999982
32.8074 0.934554 51.055
0.898154
10 0.999986
32.7773 0.934615 53.299
0.893677
脂肪
的模型選擇和驗證
分量 X 變異數 誤差 R-Sq PRESS
R-Sq(預測)
1 0.984976
282.519 0.050127 308.628
0.000000
2 0.996400
229.964 0.226824 267.199
0.101637
3 0.997757
115.951 0.610155 143.986
0.515895
4 0.999427
98.285 0.669550 127.389
0.571698
5 0.999722
57.994 0.805015 76.435
0.743012
6 0.999853
53.097 0.821480 72.109
0.757560
7 0.999963
52.010 0.825133 72.412
0.756540
8 0.999976
48.842 0.835784 76.432
0.743024
9 0.999982
34.344 0.884529 67.884
0.771764
10 0.999986
31.050 0.895604 65.116
0.781068
解釋
在此範例中,交叉驗證為 PLS 模型選擇了 10 個分量,因為它產生的平均值預測 R 最高。濕度和脂肪含量的預測 R 分別為 89.4% 和 78.1%。科學家們確定 10 分量模型最適合他們的資料。
部分最小平方 > 模型評估圖 -
模型選擇圖
模型選擇圖作為經提取或交叉驗證的分量數的函數,是 R 平方和預測的 R 平方值的散佈圖。它是模型選擇和驗證表的圖表化顯示。垂直線表明 Minitab 為 PLS 模型所選擇的分量數。如果不使用交叉驗證,則圖上不會出現預測的 R 的值。Minitab 為每個反應提供一個模型選擇圖。
使用此圖比較不同模型的建模和預測檢定力,以確定在模型中要保留的合適分量數。
輸出範例

解釋
在此範例中,所選擇的 PLS 模型具有 10 個分量,如兩個圖中的垂直線所示。分量為 10 個時,反應的平均值預測 R 的值最大。
部分最小平方 > 模型評估圖 -
反應圖
反應圖是適配和交叉驗證的適配值與實際反應的散佈圖。如果不使用交叉驗證,則圖上不會出現交叉驗證的適配。Minitab 為每個反應提供一個反應圖。
此圖顯示模型對每個觀測值的適合度和預測準確程度。檢查此圖時,請尋找下列資訊:
· 適配與交叉驗證的值之間的較大差異,表明槓桿效率點
· 這些點中的非線性模式,表明模型不能很好地適配或預測資料
輸出範例

解釋
在此範例中,濕度和脂肪含量圖沒有顯示適配反應和交叉驗證的適配反應之間的差異。兩個圖中的點都成線性模式,表明模型與資料適配良好並準確預測反應。
部分最小平方 > 模型評估圖 -
係數圖
此係數圖是一種投影散佈圖,它顯示每個預測變數的非標準化係數。Minitab 為每個反應提供一個係數圖。
將此圖與迴歸係數的輸出結合使用,以比較每個預測變數的係數的符號和量值。使用此圖更容易快速地確定模型中可能重要或不重要的預測變數。
由於此圖顯示非標準化係數,因此只有預測變數規模相同(範例,光譜資料)時才能在預測變數之間關係的量值以及反應之間進行比較。否則,使用標準化係數圖或使用載荷圖來比較用於計算分量的預測變數的權重。
輸出範例

解釋
在此範例中,預測變數(光譜資料)處於相同規模。兩個圖都表明波長 1 - 40 對反應的影響最大。對於脂肪含量和濕度,除了波長 51 - 61(與濕度正相關,與脂肪含量負相關)外,預測變數的符號相同。
部分最小平方 > 模型評估圖 -
標準化係數圖
此係數圖是一種投影散佈圖,它顯示每個預測變數的標準化係數。Minitab 為每個反應提供一個標準化係數圖。
將此圖與迴歸係數的輸出結合使用,以比較每個預測變數的係數的符號和量值。使用此圖更容易快速地確定模型中可能重要或不重要的預測變數。
由於此圖顯示非標準化係數,因此即使預測變數規模不同,也可以在預測變數之間關係的量值以及反應之間進行比較。
如果您的預測變數的規模都相同,則標準化和非標準化圖中係數的模式看上去相似。但是這些圖有可能看上去不同,原因是預測變數高度相關,從而導致係數不穩定,以及樣本標準差和總體標準差之間存在差異。
輸出範例

解釋
在此範例中,預測變數(光譜資料)處於相同規模,因此係數的模式看起來與非標準化係數圖中顯示的模式相似。係數的符號相同,但每個反應的係數之間的相對量值與非標準化係數稍有不同。
部分最小平方 > 模型評估圖 -
距離圖
距離圖是每個觀測值距 x 模型和 y 模型的距離的散佈圖。距
y 模型的距離量測 y 空間中觀測值的適合度。距 x 模型量測 x 空間中觀測值的適合度。
檢查此圖時,請尋找 x 軸或 y 軸上距離大於其他點的點。距 y 模型距離較遠的觀測值可能是異常值,距 x 模型距離較遠的觀測值可能是槓桿效率點。
輸出範例
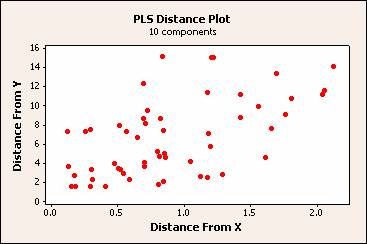
解釋
在此範例中,有幾個觀測值的距離值較大,透過刷點識別:
· 大豆樣本 41、12 和 22 距 y 模型的距離較遠,可能是異常值。
· 大豆樣本 24 和 15 距 x 模型的距離較遠,可能是槓桿效率點。
· 大豆樣本 43 距兩個模型的距離都較遠,表明它可能是異常值和槓桿效率點。
部分最小平方 > 殘差異析圖 -
殘差直方圖
標準化殘差的直方圖顯示全部觀測值的殘差異布。使用直方圖作為研究工具來瞭解資料的下列特徵:
· 典型值、波動或變異以及形狀
· 資料中的異常值
殘差的直方圖應該為鍾形。使用此圖尋找下列資訊:
此圖表趨勢... 表明...
長尾 偏斜度
遠離其他長條的長條 異常值
由於直方圖的外觀會根據用於對資料進行分組的區間數而變更,因此請使用常態機率圖和適合度檢定來評定殘差是否為常態。
輸出範例

解釋
對於大豆資料,有兩個直方圖,一個用於濕度,一個用於脂肪含量。
· 濕度的標準化殘差的直方圖顯示資料中可能存在異常值,如圖的右側遠處的長條所示。
· 脂肪含量的標準化殘差的直方圖顯示為鍾形、對稱圖表趨勢,表明殘差不偏斜,也不存在異常值。
部分最小平方 > 殘差異析圖 -
殘差常態機率圖
此圖表圖示當分布為常態時標準化殘差與其期望值。根據分析得出的殘差應該是常態分布的。實際上,對於具有大量觀測值的資料,略微偏離常態性不會嚴重影響結果。
殘差的常態機率圖應該大致為一條直線。使用此圖尋找下列資訊:
此圖表趨勢... 表明...
非直線 非常態性
尾部為曲線 偏斜度
遠離直線的點 異常值
斜率不斷變化 未確定的變數
如果資料的觀測值不足 50 個,則即使殘差是常態分布的,圖也可能在尾部顯示曲率。隨著觀測值數的減少,機率圖甚至可能會顯示更大的變異和非線性。使用常態機率圖和適合度檢定來評定小資料集中殘差的常態性。
輸出範例

解釋
對於大豆資料,脂肪含量圖的殘差顯示為一條直線。沒有證據表明存在非常態性、偏斜度、異常值或未確定的變數。濕度的殘差圖並不服從直線。幾個點落在 95% 的信賴區間之外,表明常態性存在問題。這可能是由殘差異常大的觀測值所導致。
部分最小平方 > 殘差異析圖 -
殘差與適配
此圖表圖示標準化變異數與適配。殘差應該在 0 附近隨機分散。使用此圖尋找下列資訊:
此圖表趨勢... 表明...
殘差相對適配呈扇形或不均勻分散 異變異數
曲線 缺少高次項
遠離 0 的點 異常值
在 x 方向遠離其他點的點 有影響的點
輸出範例

解釋
根據這些圖來看,殘差隨機分散在 0 附近,表明儘管有證據表明存在異常值,但資料中的關係為線性,且變異數恆定。刷圖表識別可能是異常值的點。
· 濕度圖表明大豆樣本 22 和 36 可能是異常值。兩個觀測值在距離圖中都是異常值。
· 脂肪含量圖顯示大豆樣本 39 可能是異常值。
部分最小平方 > 殘差異析圖 -
殘差與槓桿效率
殘差與槓桿效率圖是每個觀測值的標準化殘差與槓桿效率的散佈圖。檢查此圖時,請尋找下列資訊:
· 異常值 - 標準化殘差大於 +/- 2的觀測值,它在圖中位於水準參考線之外。
· 槓桿效率點 - 槓桿效率值大於 2m / n(其中 m = 分量數,且 n = 觀測值數)的觀測值,該觀測值被視為極值。它們的 x 分值遠離 0 並且位於垂直參考線(位於 x 軸上
2m / n 值處)右側。如果 2m / n 大於 1,則圖上不會顯示參考線,因為槓桿效率值始終在 0 和 1 之間。
輸出範例

解釋
此例有兩個殘差與槓桿效率圖,一個用於濕度,一個用於脂肪含量。刷圖表識別可能是異常值或具有高槓桿效率的點。
· 在濕度圖中,大豆樣本 41 和 42 在垂直線的右側,表明它們具有槓桿效率極值。大豆樣本 22 和 36 在最上面的水準線之上,表明它們是異常值。這些點在殘差與適配圖上也是異常值。
· 在脂肪含量圖中,大豆樣本 41 和 42 的位置在垂直線的右側,表明它們也是槓桿效率點。大豆樣本 27、18 和39 的位置位於水準參考線之上和之下,表明它們是異常值。樣本 39 在殘差與適配圖上也是異常值。
部分最小平方 > 殘差異析圖 -
殘差與順序
此圖表以對應觀測值的順序圖示標準化殘差。觀測值的順序可能影響結果時此圖會很有用,以時間順序或以某些其他順序(如地理區域)採集資料時可能影響結果。此圖在試驗未被隨機化的設計實驗中尤其有協助。
圖中的殘差應該在中心線附近隨機波動。檢查此圖以檢視相鄰誤差項之間是否存在任何相關性。殘差之間的相關性可以表示為:
· 殘差中的上升或下降趨勢
· 相鄰殘差的符號快速變化
輸出範例

解釋
對於大豆資料,殘差隨機分散在 0 附近。沒有證據表明誤差項彼此相關。
注意
此圖位於四合一殘差圖中,後者在一個圖表中顯示殘差直方圖、殘差常態機率圖、殘差與適配圖以及殘差與順序圖的版面。
部分最小平方 > 殘差異析圖 -
四合一殘差圖
四合一殘差圖在一個圖表視窗中同時顯示四種不同的殘差圖。此版面有助於比較這些圖以確定模型是否符合分析的假設。此圖表中的殘差圖包含:
· 直方圖 - 表明資料是否偏斜或資料中是否存在異常值
· 常態機率圖 - 表明資料是否為常態分布的、其他變數是否影響反應或資料中是否存在異常值
· 殘差與適配 - 表明變異數是否恆定、是否存在非線性關係或資料中是否存在異常值
· 殘差與資料順序 - 表明資料中是否存在因時間或資料採集順序而產生的系統化影響
輸出範例

解釋
要檢視四合一圖中每個殘差圖的解釋,請參考本主題之前每種殘差圖的個別值主題。
部分最小平方 > 分量評估 - 記分圖
記分圖是模型中第一個和第二個分量的 x 分值的散佈圖。如果前兩個分量解釋預測變數的大多數變異數,則此圖中點的配置近似反映資料的原始多維配置。要檢查預測變數中由模型解釋的變異數數量,請檢查模型選擇和驗證表中的 x 變異數值。如果 x 變異數值很高,那麼模型解釋預測變數中的顯著性變異數。
注意
如果模型包含 2 個以上的分量,您可能想要使用圖表 > 散佈圖來圖示其他分量的 x 分值。為此,請存儲 x 分值矩陣,然後使用資料 > 複製 > 矩陣到欄將該矩陣複製到欄。如果模型只有一個分量,那麼輸出中不會顯示此圖。
檢查此圖時,請尋找下列資訊:
· 槓桿效率點 - 圖中遠離大部分點的點可能是槓桿效率點,且可能對結果具有顯著效應。
· 聚集
- 聚集在一起的點可能表明資料中有兩種或更多的不同分布,可以透過不同的模型來更好地描述。
輸出範例

解釋
在此範例中,筆刷記分圖顯示上面象限中大豆樣本 36、38、40、41 和 42 可能具有高槓桿效率值。其中幾個樣本在其他圖中顯示為異常值或槓桿效率點。因為前兩個分量描述了預測變數中 99% 的變異數,所以此圖足以代表該資料。
部分最小平方 > 分量評估 -
3D 記分圖
3D 記分圖表示模型中的第一個、第二個和第三個分量的 x 分值的三維散佈圖。如果前三個分量解釋了預測變數中的絕大多數變異數,那麼此圖中點的配置便可以近似反映資料的原始多維配置。要檢查由模型解釋的變異數的數量,請檢查模型選擇和驗證表中的 x 變異數值。如果 x 變異數值很高,那麼模型解釋預測變數中的顯著性變異數。
注意
如果模型包含 3 個以上的分量,您可能想要使用圖表 > 散佈圖來圖示其他分量的 x 分值。為此,請存儲 x 分值矩陣,然後使用資料 > 複製 > 矩陣到欄將該矩陣複製到欄。如果模型僅有一個或兩個分量,那麼輸出中不會顯示此圖。
檢查此圖時,請尋找下列資訊:
· 槓桿效率點 - 圖中遠離大部分點的點可能是槓桿效率點,且可能對結果具有顯著效應。
· 聚集
- 聚集在一起的點可能表明資料中有兩種或更多的不同分布,可以透過不同的模型來更好地描述。
您還可以使用 3D 圖表工具,那樣您可以旋轉圖以便永不同的角度進行檢視。這樣您可以得到一個更完整的資料圖片,並可以更準確地識別出槓桿效率點和點的聚集。
輸出範例
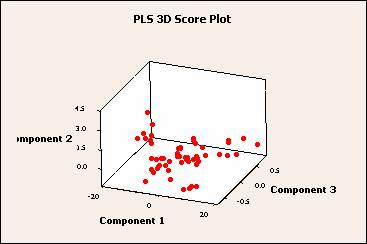
解釋
在此範例中,透過旋轉該圖,可以發現由於大豆樣本 42 具有第二個分量的極端分值,它可能是一個槓桿效率點。在其他圖上,樣本 42 被確定為潛在的槓桿效率點。
部分最小平方 > 分量評估 - 載荷圖
載荷圖是投影到到第一個和第二個分量上的預測變數的散佈圖。它顯示對第一個分量的 x 載荷描繪的第二個分量的 x 載荷。圖中每個點代表一個預測變數,都連接到了 (0,0)。
載荷圖描述了預測變數對於前兩個分量的重要性,當預測變數處於不同的刻度上時此圖尤其有協助。如果該分量解釋了模型選擇和驗證表中顯示的絕大多數 x 變異數,那麼載荷圖可以表明 x 空間中預測變數的重要性。當考慮預測變數在整個模型中的重要性時,您也必須考慮反應中由該分量解釋的變異數數量。要檢查此值,請檢查模型選擇和驗證表中的 R 預測的 R 值。
注意
如果模型包含 2 個以上的分量,您可能想要使用圖表 > 散佈圖來圖示其他分量的 x 載荷。為此,請存儲 x 載荷矩陣,然後使用資料 > 複製 > 矩陣到欄將該矩陣複製到欄。
檢查此圖時,請尋找下列資訊:
· 線之間的角度,表示預測變數之間的相關性。較小的角度表明預測變數高度相關。
· 線比較長的預測變數,在第一個或第二個分量中具有較大的載荷,且在模型中比較重要。
輸出範例

解釋
在此範例中,載荷圖顯示預測變數高度相關,因為線之間的角度很小。線的長度幾乎相同,表明預測變數的重要性相同。在第一個分量上,預測變數具有相似的正載荷,表明其重要性相同。在第二個分量上,前三個預測變數的載荷比其他預測變數的大。
檢查模型選擇和驗證表顯示前兩個分量解釋了 x 空間中 99% 的變異數、濕度中
79% 的變異數和脂肪含量中 10% 的變異數。
部分最小平方 > 分量評估 -
X 變異數矩陣圖
殘差 X 圖是 x 變異數與預測變數的線性圖。每條線代表一個觀測值,且具有和預測變數一樣多的點。使用 x 殘差矩陣圖可以識別出模型無法很好地描述的觀測值或預測變數。預測變數處於相同刻度上時,此圖最有協助。
理想情況下,圖上的線應緊靠在一起並且在 0 附近。
· 當這些線在 x 軸上的相同點處斷開時,模型無法很好地描述該點處的預測變數。
· 當圖中某條線偏離其他線時,模型無法很好地描述由該線表示的觀測值。
使用 x 殘差矩陣圖來檢視殘差中的一般圖表趨勢並識別出存在問題的區域。然後檢查輸出中顯示的
x 殘差以查明模型無法很好地描述的觀測值和預測變數。
輸出範例

解釋
在此範例中,殘差接近於 0,表明模型描述了預測變數中的絕大多數變異數。使用這麼小的 x 殘差異無法檢測到模型無法很好地描述的觀測值或預測變數。
部分最小平方 > 分量評估 - 計算 X 圖
計算 X 圖是 x 計算值與預測變數的線圖。每條線代表一個觀測值,且具有和預測變數一樣多的點。使用此圖來識別出模型無法很好地描述的觀測值或預測變數。預測變數處於相同刻度上時,此圖最有協助。
該圖是 x 殘差圖的補充。兩個圖結合可以形成原始預測變數值的圖。具有比原始的 x 值小或大很多的 x 計算值的預測變數無法由模型很好地描述。
輸出範例
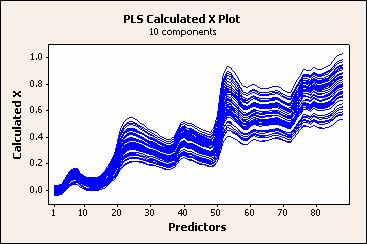
解釋
在此範例中,絕大多數 x 計算值都非常接近於原始的預測變數值,表明模型描述了預測變數中的絕大多數變異數。
Regression > Partial Least Squares > more


什麼是交叉驗證?
交叉驗證可以計算潛在模型的預測能力,以協助您確定要保留在模型中的適當的分量數。如果不知道理想的分量數,建議使用交叉驗證。
當資料中包含多重反應變數時,Minitab 將同時驗證全部反應的分量。Minitab 將計算、顯示併圖示每個反應的 PRESS 和預測的 R,但根據最低平均值 PRESS 值和最高平均值預測 R 來選擇分量數。
交叉驗證製程
對於每個潛在模型,Minitab 將進行下列操作:
1 根據交叉驗證方法,忽略一個觀測值或一組觀測值。
2 不考慮該觀測值/觀測值組的情況下,重新計算模型。
3 使用重新計算的模型預測忽略的觀測值/觀測值組的反應或交叉驗證的適配,並計算交叉驗證殘差異。
4 重複步階 1 - 3,直到忽略並適配了全部的觀測值。
5 計算預測的平方和 (PRESS) 和預測的 R 的值。
對於每個模型執行步階 1 - 5 後,Minitab 將選擇具有可以產生最高的預測 R 和最低的 PRESS 的分量數的模型。具有多重反應變數時,Minitab 將選擇具有最高平均值預測 R 和最低平均值 PRESS 的模型。
如果不使用交叉驗證,Minitab 會將分量數設定為 10 或模型中的預測變數數兩者中較小的那個值。
實踐者通常使用交叉驗證來估計 PLS 模型的分量數,然後透過檢定集使用預測來估計模型的預測能力。
什麼是預測
您可以使用 PLS 模型來檢定它的預測品質並預測新的反應。
· 檢定預測品質 - 將 PLS 模型應用於類似但獨立於用於估計 PLS 模型的檢定資料集的檢測資料集。使用該模型來計算檢定集中每個觀測值的新反應值並比較預測的反應和實際的反應。Minitab 提供一個檢定 R,它表示模型預測反應的品質。
· 預測新的反應 - 使用 PLS 模型來估計一組沒有反應資料的預測變數的新反應值。沒有反應資料,Minitab 無法計算檢定 R。
多反應變數
PLS 可以適配個別值模型中的多重反應變數。因為 PLS 以多元方式對反應變數建模,所以結果可能與為反應變數單獨計算出的值顯著不同。僅當它們相關時,您應該在個別值 PLS 模型中的對多重反應建模。
Minitab 為每個反應都顯示一個變異數分析表、預測反應表、模型選擇和驗證表、係數表和適配與殘差表。Minitab 為每個反應都提供下列各種圖:模型選擇圖、反應圖、係數圖、標準化係數圖和全部的殘差圖。
什麼是殘差
Minitab 提供三種類型的殘差:
· 常規殘差:觀測值 - 預測值。
· 標準化殘差:常規殘差 / 常規殘差的標準差。
標準化消除了資料點位置對於預測值或因子的影響。
· 學習化已刪除殘差:對於 ith 資料點,公式遵循與標準化殘差相同的表達方式。但是,計算第i個 學習化已刪除殘差時適配和標準差都是在刪除第i個觀測後得到的。與標準化殘差相比,學習化已刪除殘差在出現異常資料點時會變大。
模型假設
迴歸和變異數分析製程關於誤差做出下列假設:
· 誤差為常態分布,且平均值為 0。
· 誤差變異數不會為不同因子水準或根據預測反應的值而發生變更。
· 每種誤差都獨立於全部其他誤差。在所設計的實驗中,獲得獨立誤差的最好方式是隨機化實驗的實驗順序。
在分析中檢定這些假設的有效性。殘差是誤差的最佳估計值。因此,可以使用殘差圖以圖表方式檢查每個假設。
如果模型違反這些假設,則分析的結果可能有誤導性。範例,如果誤差相互關聯,則可能會錯誤地估計係數的標準誤差,從而導致錯誤的 t 值和 p 值。
直方圖和常態性
下列是從常態分布中抽取的九個資料集樣本。這些樣本沒有問題;但是,這些直方圖中大多數看起來不是鐘形,這描述了為什麼不應該使用直方圖來判斷資料的常態性。判斷資料是否為常態分布需要使用常態機率圖。
隨機產生樣本的直方圖

每個樣本包含常態分布中的 24 個觀測值。
非常態性的效應
迴歸和變異數分析的一個假設為殘差來自常態分布。但是,如果設計僅有固定因子,設計為平衡或接近平衡,且具有相當多的觀測值,則略微偏離常態性不會嚴重影響結果。
發現非常態圖表有趨勢時該怎麼做
可能難以正確指出常態機率圖中明顯偏離常態性的原因。可能的原因包含:
· 齊次變異數假設失敗
· 殘差異常大(異常值)
· 模型中缺少重要變數
· 資料來自非常態總體
對於完整分析,請將常態機率圖與其他診斷圖以及適合度統計量結合使用。
如果發現非常態圖表趨勢:
1 使用其他診斷圖檢視非常態性是否由非常態總體中的資料之外的因素所導致。
2 使用統計 > 基本統計 > 常態性檢定來執行常態性檢定。
3 如果確定資料來自非常態總體,則可以在繼續分析之前轉換資料。請參見轉換反應變數。
注意
修復不等變異數問題的轉換通常也修復常態性問題。
轉換反應變數
殘差表示異變異數或非常態性時,必須進行轉換。
您可能還會發現在模型表現出顯著缺適性時資料轉換非常有用,而且這種轉換在反應曲面實驗的分析中尤為重要。假設在模型中包含全部顯著的交互作用和二次項,但缺適性檢定表明需要高次項。轉換可以消除缺適性。
如果資料轉換修正了此問題,使用迴歸分析比用其他可能更複雜的分析方法要好一些。迴歸分析或實驗設計分析的結果可以指導我們選擇合適的資料轉換方法解決不同的問題。
Box-Cox 轉換是最常用的變異數穩定轉換。在下面第一個圖表中,殘差表示異變異數。第二個圖表顯示變異數穩定轉換之後的殘差。適配的刻度(x 軸)變更,而變異數變為恆定。

常態機率圖中的圖表趨勢
下列圖表趨勢違反了誤差為常態分布這一假設。
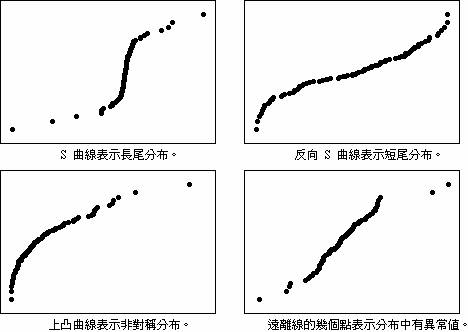
殘差與適配圖中的圖表趨勢
下列圖表趨勢顯示異常值和對誤差為恆定這一假設的衝突。
異常值圖
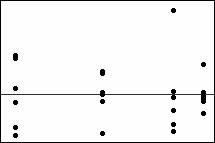
右上角的殘差比圖中其他全部都大很多,因此為異常值。如果異常值過多,則模型可能不妥當。異常值可能是由於量測錯誤所導致。應該調查異常值以確定其原因。
異變異數圖
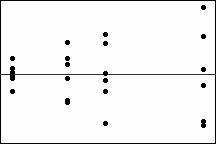
殘差的變異數隨適配增加。請注意,隨著適配的增加,殘差在零殘差線周圍分散得更廣,指明不等的(非恆定)變異數。此圖表趨勢表明誤差變異數隨平均值的增加而增加。資料的轉換會有助於穩定這些變異數。
發現圖表有趨勢時該怎麼做
如果圖顯示... 執行此操作...
異變異數 1 使用統計 > 變異數分析 > 變異數相等檢定來檢定相等變異數的假設。
2 如果圖或檢定表明變異數不等,則考慮轉換反應變數。
異常值或有影響的點 1 驗證觀測值不是量測或資料錄入錯誤。
2 考慮執行分析時不包含此觀測值來檢視它是否影響結果。
缺少高次項 增加此項並重新適配模型。
殘差與順序圖中的圖表趨勢
下列圖表趨勢違反了誤差彼此獨立這一假設。

發現圖表有趨勢時該怎麼做
殘差與資料順序圖中的圖表趨勢表明誤差不是獨立的。此指示可能嚴重影響分析的結論,因此應該至少考慮下列一種補救措施:
· 由於誤差的非獨立性往往難以修正,因此如果要進行設計的實驗,應該盡量透過隨機化試驗以防止出現這種問題。
· 向模型中增加時間效應以消除誤差項的相關。範例,正在檢視幾個月期間的日收入。增加表示一周中某天的因子會消除誤差項中的非獨立性。
· 考慮時間序列製程(如 ARIMA)以解決誤差項中的自相關。
詳細資訊請到官方網站進一步了解: http://www.minitab.com.tw/
和 http://www.minitab.com/
聲明: 本文純粹學術性研討, 內容所提及任何關於 Minitab 專有創作文字, 圖像與架構…等皆屬Minitab Inc. 版權所有, 嚴禁商業上轉貼使用.
沒有留言:
張貼留言