有學過6
sigma的同學, 一定知道 Minitab這套軟體, 因為它把6 sigma實用化了. 過去 Minitab 並沒有中文版, 但對岸有人將它漢化後, 官方也出簡體中文版, 使用簡體中文版會比英文版更friendly, 但畢竟兩岸語文還是有差異, 尤其專有名詞上的差異更讓人難以適從, 例如常態分配 v.s. 正态分布; 品質 v.s. 质量; 巨集 v.s. 宏; 變異數分析
v.s.方差分析; 進階 v.s. 高级…
官方目前沒有繁體中文版.~可惜! 希望 Minitab TWN公司能早日完成繁體中文版的 Minitab. ~期待!
先前談到 Tutorials 教學課程, 了解如何使用 Minitab 各項功能。而在Help 協助 > StatGuide 統計指南中, 則對於輸出的結果有詳細的解釋說明:
Basic Statistics > Normality Test

常態性檢定 > 匯總
許多統計製程都假定資料服從常態分布。為了驗證此假設,可對資料執行常態性檢定。
Minitab 提供三種可供選擇的常態性檢定:
· Anderson-Darling - 此檢定具有極好的檢定力,並且在分布的高值和低值中檢測對常態性的偏離時特別有效。
· Ryan-Joiner(與 Shapiro-Wilk 類似) - 此檢定具有極好的檢定力。它基於樣本資料與期望從常態分布中獲得資料之間的相關。
· Kolmogorov-Smirnov - 這是常見的常態性檢定,但檢定力比其他兩種檢定要低。
每個檢定的結果都帶有常態機率圖,這有助於確定資料是否服從常態分布。
資料描述
營養學家選擇隨機的 13 瓶食用油樣本,以確定飽和脂肪的平均百分比是否不同於宣傳的 15%。以前的研究表明,總體標準差為 2.6%。
使用單樣本 Z 檢定似乎很合適,但常態性假設需要進行驗證。營養學家選擇 a 水準 0.10 進行檢定。
資料:
脂肪.MTW (在樣本資料檔案夾中)
常態性檢定 > 圖表 - 機率圖
如果資料完全呈常態分布,機率圖上的資料點將會形成一條直線。參考線是基於 Minitab 透過樣本估計的參數的適配累積分布函數。
根據您選擇的常態性檢定,機率圖並沒有什麼變化,但圖例中的檢定統計量和 p 值可能會不同。
輸出範例

解釋
食用油資料圖顯示點合理分布在參考線附近,這表明資料服從常態分布。
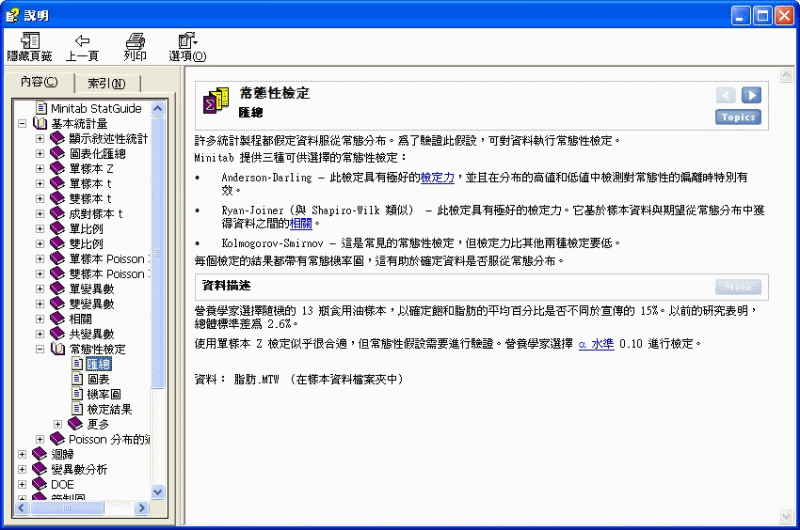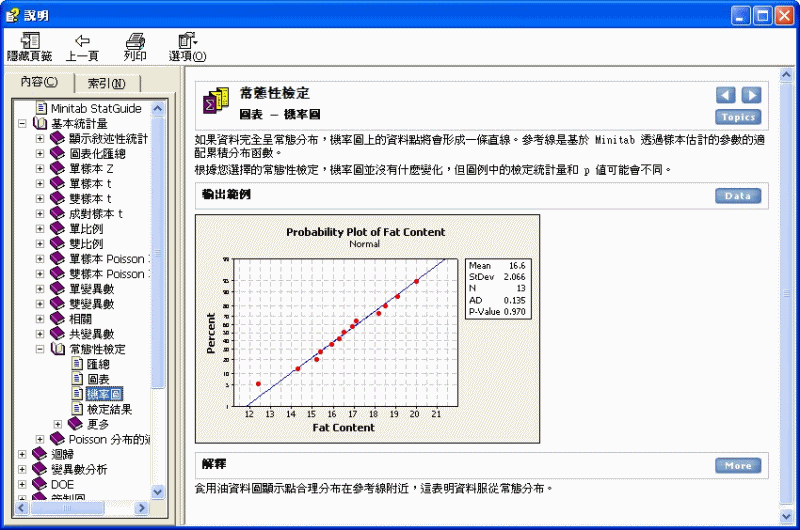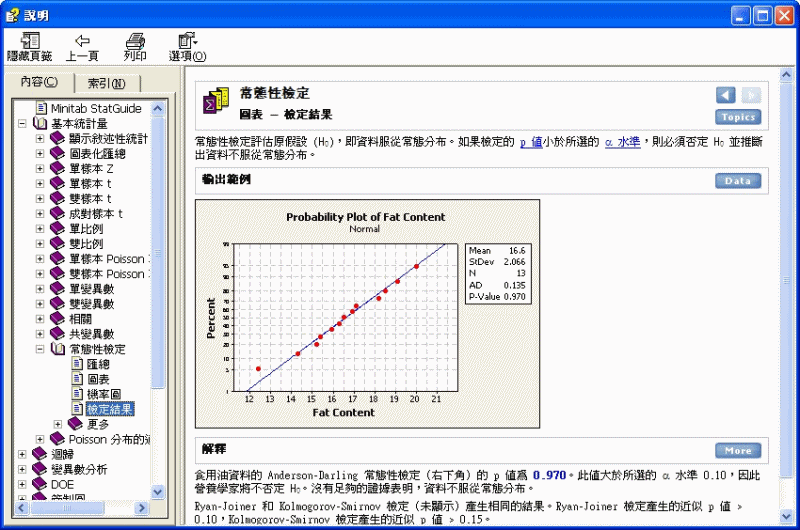
常態性檢定 > 圖表 - 檢定結果
常態性檢定評估原假設 (H0),即資料服從常態分布。如果檢定的 p 值小於所選的 a 水準,則必須否定 H0 並推斷出資料不服從常態分布。
輸出範例
解釋
食用油資料的 Anderson-Darling 常態性檢定(右下角)的 p 值為 0.970。此值大於所選的 a 水準
0.10,因此營養學家將不否定 H0。沒有足夠的證據表明,資料不服從常態分布。
Ryan-Joiner 和 Kolmogorov-Smirnov 檢定(未顯示)產生相同的結果。Ryan-Joiner 檢定產生的近似 p 值 > 0.10,Kolmogorov-Smirnov 檢定產生的近似 p 值 > 0.15。
Basic Statistics > Normality Test > more

從機率圖中評估資料的形狀
當圖中的點處於相對直線上時,常態機率圖驗證常態性的假設。如果不是這樣,則仍可取得有關資料形狀的一些資訊,具體取決於圖偏離直線的程度。
範例,下面的機率圖和直方圖來自向右傾斜的資料集。


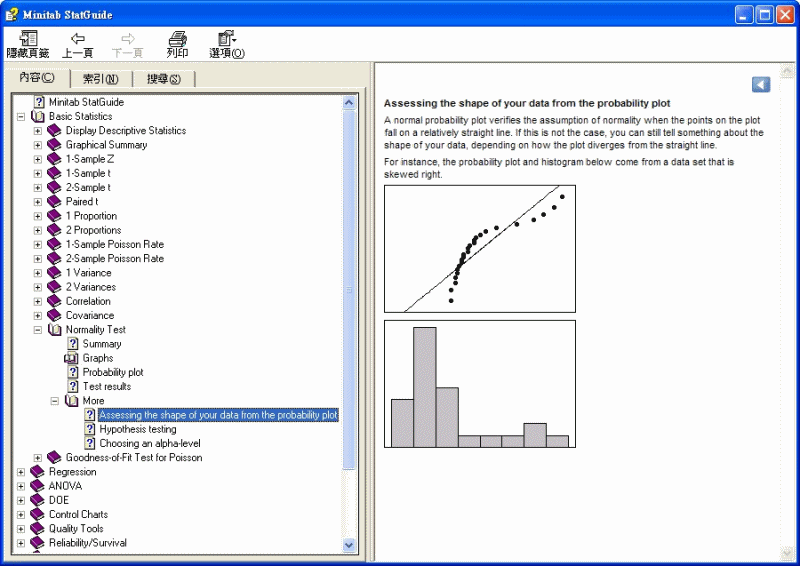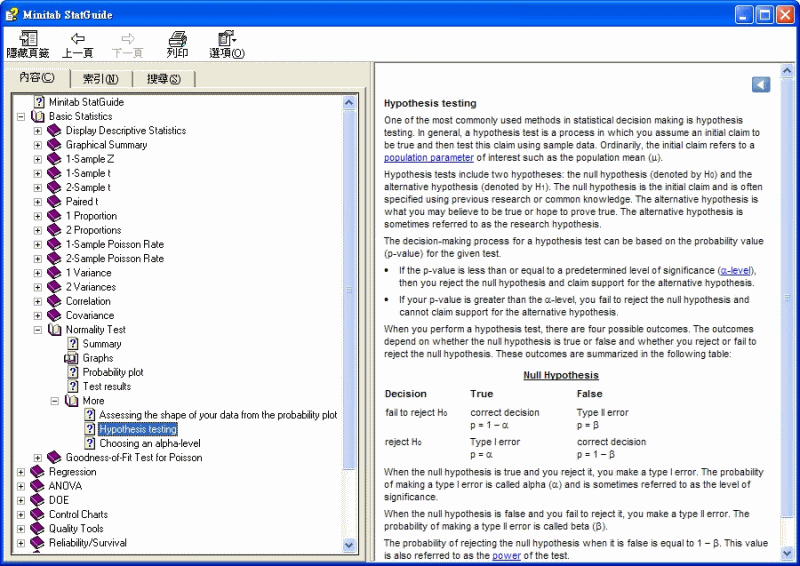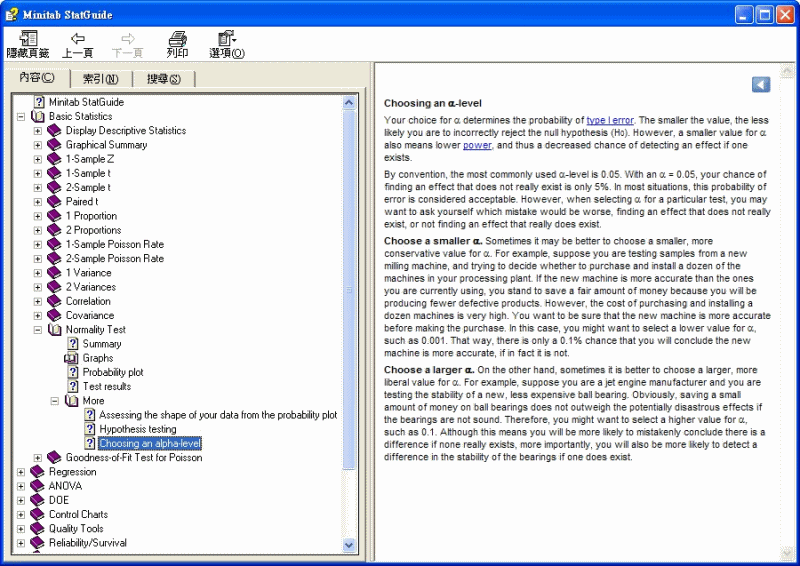
假設檢定
假設檢定是統計決策中最常用的方法之一。一般而言,假設檢定是一種假定初始聲明為真,然後使用樣本資料檢定該聲明的製程。通常,初始聲明是指相關的總體參數,如總體平均值 (m)。
假設檢定包含兩個假設:原假設(以 H0 表示)和備擇假設(以 H1 表示)。原假設是初始聲明,且通常使用先前的研究或常識進行指定。備擇假設是可以相信為真實或有望證明為真實的內容。備擇假設有時稱為研究假設。
假設檢定的決策製程可以基於給定檢定的機率值(p 值)。
·
如果 p 值小於或等於預先確定的顯著性水準(a 水準),則否定原假設,並聲明支援備擇假設。
· 如果
p 值大於 a 水準,則不能否定原假設,且不聲明支援備擇假設。
執行假設檢定時,有四種可能的結果。結果取決於原假設的真假以及能否否定原假設。下表中匯總了這些結果:

如果原假設為真,但否定了原假設,則發生類型 I 錯誤。發生類型 I 錯誤的機率稱為阿爾法 (a),有時也稱為顯著性水準。
如果原假設為假,但未能否定它,則發生類型 II 錯誤。發生類型 II 錯誤的機率稱為 b。
原假設為假時,否定它的機率等於 1 - b。此值也稱為檢定的檢定力。
選擇 a 水準
對 a 的選擇決定類型 I 錯誤的機率。此值越小,錯誤地否定原假設 (H0) 的幾率就越小。但是,a 值越小就意味著檢定力越低,並因此降低了檢測到效應(如果存在)的幾率。
按照慣例,最常用的 a 水準為 0.05。a = 0.05
表示發現實際並不存在的效應的幾率僅為 5%。大多數情況下,認為這種出現錯誤的機率可允收。但是,對特定檢定選擇 a 時,可能需要考慮何種錯誤更嚴重:發現實際不存在的效應,或未發現實際存在的效應。
選擇較小的 a。有時選擇較小、較保守的 a 值更好。範例,假設要檢定新銑床中的樣本,並嘗試決定是否購買並在加工車間中安裝一批這種機器。如果新機器比當前使用的機器更精確,則會節省大量資金,因為生產的殘次品將會減少。但是,購買和安裝一批機器的成本非常高。購買前需要確信新機器更加精確。這種情況下,可能需要選擇較低的 a 值,如 0.001。這樣,如果實際上並非如此,將斷定新機器更精確的幾率也僅為 0.1%。
選擇較大的 a。另一方面,有時選擇較大、較寬鬆的 a 值更好。範例,假設噴氣發動機製造商要檢定一種價格較低的新滾珠軸承的穩定性。很明顯,如果滾珠不合格,則節省的少量滾珠成本沒有潛在災難性後果的代價值得重視。因此,可能需要選擇較高的 a 值,如 0.1。儘管這意味著在不存在差異的情況下將更可能錯誤地斷定存在差異,但更重要的是更可能檢測到軸承穩定性中的差異(如果存在)。
詳細資訊請到官方網站進一步了解: http://www.minitab.com.tw/
和 http://www.minitab.com/
聲明: 本文純粹學術性研討, 內容所提及任何關於 Minitab 專有創作文字, 圖像與架構…等皆屬Minitab Inc. 版權所有, 嚴禁商業上轉貼使用.
沒有留言:
張貼留言